Added new geometric clipping filter + unit test. #200
Conversation
|
@kanderso-nrel @cdeline @matt14muller @mdeceglie PR for clipping filter. |
…ata sampling frequency and derivative threshold cutoff. Set as a default parameter, can be overridden by the user.
…ing filter. Uses plotly to generate.
|
I'm trying this functionality out currently. One problem I'm having is that NaN values appear to be removed from the index. This is an issue if you try to mask by the output of the geometric clipping filter. For instance: I pass in a 120k length df with the first 20k values being NaN. The filter boolean mask coming out has a length of 100k. This appears to happen after your comment '#Outlier removal statement'. It would be better if your boolean output is guaranteed to have the same length as the input power_ac |
|
@cdeline I can make that change here today, will include a default of False for any of the filtered items on the mask. |
|
@cdeline @mdeceglie @kanderso I gave the matplotlib build a shot for interactive mode--this is what I came up with:
It does save as an html and it is interactive (requires the mpld3 package to do this) but the zoom quality is not amazing. If anyone has suggestions on how to improve this, let me know. Otherwise, I've kept things with plotly as the graphics are significantly better, and just added plotly as a package for the time being to the requirements.txt file; the builds look good with this. |
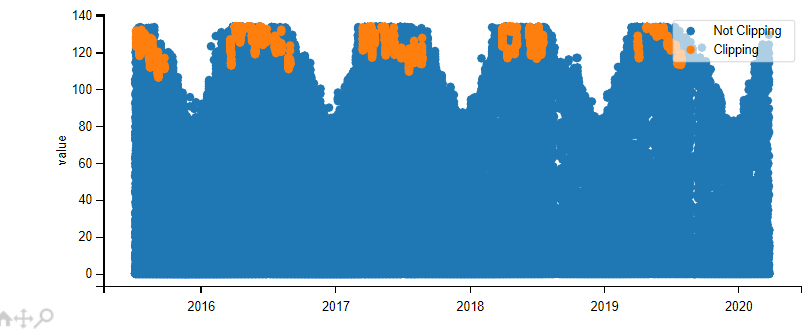
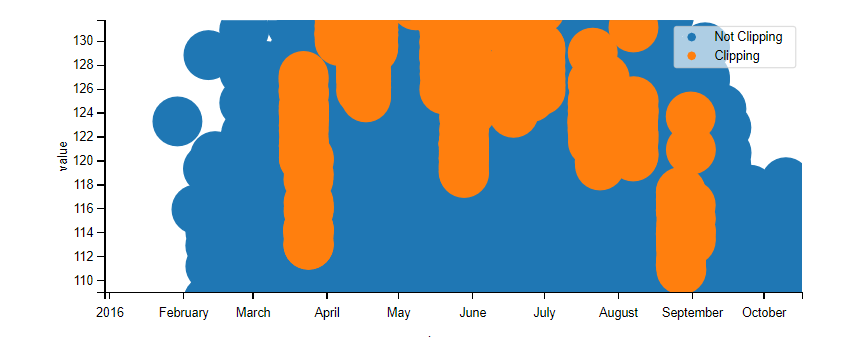
|
Just thinking about the plotting function, sounds like either way (plotly or mpld3) this functionality would require a new dependency. Looks like plotly is about as big a dependency as numpy or pandas, so not as big as scipy but not small either. Taking a step back for a moment, is the motivation to use plotly (or mpld3) to be able to save the clipping figure to HTML for later viewing? That functionality seems useful for our internal processes, but I wonder if it necessarily needs to live in RdTools instead of one of our internal packages. If we do think it's worth keeping in RdTools, we should consider if the other plotting functions could be improved by using plotly instead of mpl. |
|
@kanderso I agree that we may want to take a step back regarding how we want to handle plotting, and whether it should be matplotlib only or plotly only (or a mixture of both??). Obviously I do have a bias as I think the graphics on plotly look amazing compared to those in matplotlib, but I don't want that to be a deciding factor here. mpld3 saves matplotlib where it can be accessed as an interactive html for later use. I've done a little bit of playing around with matplotlib in interactive mode in jupyter notebook, but generally it does require dependencies (I tried it with the ipympl package add on, where you can declare matplotlib as a widget--see https://towardsdatascience.com/how-to-produce-interactive-matplotlib-plots-in-jupyter-environment-1e4329d71651). Generally I've found that no matter what, we will probably be adding some new package as a dependency to get interactive plotting. |
|
My opinion- matplotlib is not terribly user-friendly, and doesn't do user-interactive behavior very well. Plotly sounds like it's a good solution for interactive plots and I'd like to get to know how to use it better. |
…gging the Travic CI build failure)
…ated to 'signal' in plotting.
…ile--from pandas 0.24.0
…ethod for pandas daily resampling with quantile.
 mdeceglie
left a comment
mdeceglie
left a comment
There was a problem hiding this comment.
Looks good. I've left a few more comments. Once you consider these and get it finalized, please run and commit the affected notebooks then we should be good to merge.
rdtools/filtering.py
Outdated
| # Throw a warning that we're expecting time zone-localized data | ||
| warnings.warn("Function expects a time zone-localized time series. " | ||
| "For best results, pass a time zone-localized time series.") |
There was a problem hiding this comment.
I'd say either not raise a warning at all, and let the user-facing docstring speak for itself, or only raise a warning if we can detect there may be a problem.
If we do raise it I would revise to read: "[thing that was detected] Function expects timestamps in local time. For best results pass a time-zone-localized time series localized to the correct local time zone"
| if not all(power_ac.sort_index().index == power_ac.index): | ||
| raise IndexError( | ||
| "Time series index has not been sorted. Implement the " | ||
| "sort_index() method to the time series to rerun this function.") |
There was a problem hiding this comment.
What's the reasoning for changing to an error rather than letting the function sort?
rdtools/filtering.py
Outdated
| power_ac : pandas.Series | ||
| Pandas time series, representing PV system power or energy with | ||
| a timezone-localized pandas datetime index. |
There was a problem hiding this comment.
| power_ac : pandas.Series | |
| Pandas time series, representing PV system power or energy with | |
| a timezone-localized pandas datetime index. | |
| power_ac : pandas.Series | |
| Pandas time series, representing PV system power or energy. | |
| Timestamps must be in local time. |
rdtools/filtering.py
Outdated
| power_ac : pandas.Series | ||
| Pandas time series, representing PV system power or energy with | ||
| a timezone-localized pandas datetime index. |
There was a problem hiding this comment.
| power_ac : pandas.Series | |
| Pandas time series, representing PV system power or energy with | |
| a timezone-localized pandas datetime index. | |
| power_ac : pandas.Series | |
| Pandas time series, representing PV system power or energy. | |
| Timestamps must be in local time. |
mdeceglie
left a comment
There was a problem hiding this comment.
Looks great. Let's go ahead and merge. Thanks everyone!
 cdeline
left a comment
cdeline
left a comment
There was a problem hiding this comment.
Nice job, thanks for keeping this moving forward.
* Model chains (#117) * Add normalized_filter() function to replace the mannual filter in example * Initial working system analysis class * system analysis version that reproduces notebook results Works for both sensor and clearsky workflows * Improve underlying analysis These improvements slightly change the clearsky results relative to the existing version of the notebook. * Allow poa, temperature, and temperature_coefficient to be None This leaves room for BYO modeled PV perofmrance in the future * Add system_analysis to rdtools namespace * Basic example of system_analysis() use * Update degradation_and_soiling_example.ipynb 1) Use apparent zenith in irradiance calculations instead of zenith 2) Apply clearsky filter based on poa irradiance rather than insolation 3) Include ground diffuse in irradiance transposition calculations * Update system_analysis_example notebook Update notes and change initial poa calculation to include ground diffuse * Add a plotting module * Update notebook to use plotting module * Add plotting methods * update system_analysis example notebook * add docstrings * Delete model chain dev notes * add matplotlib to setup.py and update requirements * change matplotlib version * Move docstring to class * renormalization bug fix * Update temperature input interface (Also fix merge bug in plotting) * update docstring for new temperature interface * Remove __init__ docstring * update class name to CamelCase * update kwarg explanatations in docstrings * remove model parameter from calc_clearsky_poa() It is still addressable through kwargs passed to pvlib * Update SystemAnalysis_example.ipynb * Reformat dosctrings to numpy style * command style docstrings * Remove duplicate line * Update plotting docstrings to numpy style * Format normalized_filter docstring according to numpy style Other docstrings in this module have been updated in #125 * Add an ad hoc filter example to the notebook * Fixes system_analysis bug #132 when pv_nameplate is passed into syste… (#133) * Fixes system_analysis bug #132 when pv_nameplate is passed into system_analysis object. * typo fix Co-Authored-By: Kevin Anderson <[email protected]> * add bins parameter to plotting.degradation_summary_plot from #132 (cherry picked from commit efcbe2e) # Conflicts: # rdtools/plotting.py * plotting bug fix * Drop py2.7 and add 3.7 and 3.8 to testing (#135) * Drop 2.7 and add 3.7 and 3.8 to testing, update docs. * creating DatetimeIndex directly is deprecated, switch to pd.date_range * require pandas < 1.0.0 * bump requirements.txt numpy to 1.17.3 for testing on py3.8 * more requirements.txt updates for py3.8 wheel availability * Update v2.0.0.rst * add matplotlib to requirements * matplotlib 3.1 * matplotlib * merge pytests and jupyter example * PVLib > 0.7 changes to cell_temp calculation * Modelchain pytests (#196) * pytests for system_analysis. coverage: 91%. * rename system_analysis.py to analysis.py. Rename class to RdAnalysis. Update pvwatts_kws to match Master updates * Allow temp_model_params to either be string or dict with 'a','b', 'deltaT' keys * update calc_cell_temperature for pvlib > 0.6.3, use energy_normalized in normalize_with_pvwatts * Warn if temp coefficient not passed into normalize_with_Pvwatts instead of exit with error. * Add tables=3.6.1 to requirements.txt to allow clearsky analysis * add tables to setup.py since it appears to be a required pvlib for the clearsky workflow and not installed by default. * Add RdAnalysis notebook for pvdaq4 system * add max_timedelta=15T and clearsky poa calculation update to pvdaq4 standard notebook example * Sphinx release notes for 2.1.0 updated and API update Co-authored-by: Michael Deceglie <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> * Update tests, include tables in setup.py * suppress import warnings for soiling module. * Change warning suppression from warnings.resetwarnings to with warnings.catch_warnings(). Re-run notebooks * Model chains exp energy (#232) * enable normalize_with_expected_energy. * Update RdAnalysis_example.ipynb with manually defined power_expected option. * Add post-filter error check for < 2 yrs data per kanderson * Remove error message for no thermal model if power_expected is passed in. * remove tcell_filter from filter list if power_expected is passed in but not cell_temperature * pep8 compliance * more robust frequency check * shorten long lines * Model chains set clearsky (#233) * Move CS inputs to new set_clearsky function: pvlib_location ,pv_tilt, pv_azimuth, clearsky_poa, clearsky temp, albedo * Explicit error message if set_clearsky not run prior to clearsky_analysis. * remove Py2.7 check in block 3 of RdAnalysis_example.ipynb * boost analysis.py test coverage to 94% * add pv_energy pytest case. Change to ValueError rather than basic Exception when set_clearsky hasn't been run. Co-authored-by: Kevin Anderson <[email protected]> * improve index equality conditional * pep8 cleanup * change dict key syntax * Clarify behavior when pv_nameplate is omitted * Useful errors for plotting methods * update requreiments for tables * reduce minimum version of tables * Delete RdAnalysis_example.ipynb * Remove max_timedelta parameter use in PVDAQ example * Move sun position calculation to clearsky section of example This brings the clearsky results into better allignement with the objected oriented example, now sun position is calculated after interpolation on both * Update chage log version number * Allow warning for experimental modules * pep8 analysis_test.py * Change module and class names * Update example with new module/class name * Fix outdated ref to system_analysis * Update api.rst with analysis chains module name * Fix changelog underline length * update index.rst with TrendAnalysis info * poa -> poa_global * cell_temperature -> temperature_cell * ambient_temperature->temperature_ambient * temperature_coefficient->gamma_pdc * temperature_model docstring * pv_nameplate->power_dc_rated * clearsky_poa->poa_global_clearsky * clearsky_temperature_cell->temperature_cell_clearsky * clearsky_temperature_ambient->temperature_ambient_clearsky * Align yoy and srr parameters with functional API * Use `case` in plotting methods * Change notebook kernel * weakly privatize some methods * Update rdtools/analysis_chains.py Co-authored-by: Kevin Anderson <[email protected]> * Interpolate windspeed * Update rdtools/analysis_chains.py Co-authored-by: Kevin Anderson <[email protected]> * implement review suggestions * more TrendAnalysis tests to improve coverage * cleanup * Fix copy/paste error in notebook * change _calc_cell_temeprature parameter order * More elegant error if filtering results in empty series * Changelog consolidation * change log update Co-authored-by: cdeline <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> * add beta version to change log * add missing parenthesis * add TrendAnalysis notebook to gallery * good merging gone bad * fix analysis_chains_test.py * pin numexpr to 2.7.1 in requirements-min.txt * Update changelog with beta release * Fix typo in TrendAnalysis docstring (#264) * parameters -> params * changelog * Consecutive cleaning logic (#199) * Remove consecutive cleaning filter * Change day_scale default to 13 and raise warning for even values * Update soiling tests * Run notebooks * Update changelog * changelog adjustment * Update rdtools/soiling.py Co-authored-by: Kevin Anderson <[email protected]> * keep invalid intervals at beginning and end * Revert "keep invalid intervals at beginning and end" This reverts commit b3f5efc. * keep invalid intervals at beginning abd end This revision properly hanldes the trim option * Handle consecutive invalid intervals correctly for random_clean * Remove outdated comment * Adjust trend_analysis soiling test * Add a warning for >20% invalid data and random cleaning assumptions * Run notebooks degradation_and_soiling_example.ipynb exhibits a small change in the clearsky degradation results attributed to changes in random number generator state from soiling workflow changes * patch test * Add outlier factor to adjust cleaning detection sensitivity * fix flake8 errors * Add a test for outlier_factor * add outlier_factor to change log * add #234 to change log * Add invalid interval retention at start and end to change log * Clean up review suggestions * add references to #272 * fix line length * parametrize some tests * update changelog * Update the notebooks Only some warnings changed slightly * change min_interval_length default from 2 to 7 * fix line length * Add Matt to the change log contributors Co-authored-by: Kevin Anderson <[email protected]> * Issue #120 Revise NaN pixel handling in clearsky_temperature.py (#274) * Revise NaN pixel handling in clearsky_temperature.py. Raise specific warning. Fixes #120 * Changelog update * rewrite cs tamb test in pytest style * add test for not-on-land Co-authored-by: Kevin Anderson <[email protected]> * Test suite warning clean-up (#273) * suppress experimental module warnings * close figs to avoid pyplot warning * use odd day_scale value * don't use deprecated check_less_precise * prevent pandas warning about average of non-numeric types * soiling warnings * interpolation warning * add notes * cleaner suppression for soiling warning * revert unnecessary changes * units cleanup (#276) * Update requirements files (#275) * bump numpy version to handle windows compat issue * bump pygments and jinja2 using dependabot reccs * add missing indirect dependencies to requirements.txt * add missing indirect dependencies to notebook_requirements.txt * changelog * partially un-bump numpy * update nbsphinx version in setup.py spatialaudio/nbsphinx#563 Co-authored-by: Michael Deceglie <[email protected]> * add intersphinx so that type links work (#258) * add intersphinx so that type links work [Sphinx intersphinx](https://www.sphinx-doc.org/en/master/usage/extensions/intersphinx.html) is not added by default, it must be enabled and configured. Added links for: * python * numpy * pandas * scipy this will create links for types like `float`, `dict`, _etc_. and `pandas.DataFrame`, `numpy.ndarray`, _etc_. * remove trailing single quote in doc confs Co-authored-by: Michael Deceglie <[email protected]> * add pvlib intersphinx * addresses #241 * add mpl intersphinx url * fix up docstring types * more type fixes * python 3.8 -> python 3 * changelog * make soiling docstrings more consistent * fix indents in soiling docstrings * fix unexpected indent * Get the bulleted lists working in sphinx * attempt to get tuple type link working * Attempt to get type links working on TrendAnalysis * Fix trailing whitespace * type link adjustments * change from datetime to pandas timedelta in TrenAnalysis docs * Couple more link type adjustments * add type aliases * remove numpy.array Co-authored-by: Michael Deceglie <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> Co-authored-by: Michael Deceglie <[email protected]> * Store filter components on TrendAnalysis (#263) * add attributes * test * changelog * unrelated linting * bug fixes * remove unnecessary default filter, test * fix up index union funny business * preliminary fix for #266 * add test to cover new warnings * improve warning messages * expand tests * delete extra blank line Co-authored-by: Michael Deceglie <[email protected]> Co-authored-by: Michael Deceglie <[email protected]> * Loosen soiling input check to allow implicit daily index (#279) * remove empty line in pending.rst * use pd.infer_freq instead of checking index.freq directly * add test * add test for other warnings/errors too, for coverage * Adjust trend analysis interpolation behavior (#278) * Interpolate things onto pv index * add test for interpolation behavior * Update rdtools/test/analysis_chains_test.py Co-authored-by: Kevin Anderson <[email protected]> * Test set_clearsky interpolation * consolidate dummy series in test Co-authored-by: Kevin Anderson <[email protected]> * Plotting function allows data gap visualization (#282) * add 'usage_of_points' calculation to degradation.py. Seems to work ok now.. * usage of points pytest * add 'usage_of_points' to rd_result output * plotting function update add 'detailed' option, = False by default * PEP8 updates * streamline color selector with map instead of apply * add detailed=True kwarg to test_degradation_summary_plots_kwargs * Update plotting docstring. Add changelog entry. Co-authored-by: Kevin Anderson <[email protected]> Co-authored-by: Michael Deceglie <[email protected]> * Update TrendAnalysis notebook to avoid filter index mismatch warning * Adjust TrendAnalysis interpolations for index mismatch (#285) * dedent non-pv inputs * dedent clearsky inputs as well * add basic test * Use interval averages for clear-sky irradiance modeling (#281) * prelim 1-min+aggregate fix * update test asserts * add manual high-res sim+aggregation to DKASC notebook * set first value to nan * update from review: backfill change * add solar_position_method kwarg to TrendAnalysis.set_clearsky * maybe one day I'll learn to test changes prior to pushing * explicitly set default method=nrel_numpy * add test for solar_position_method kwarg using pytest-mock * use method='ephemeris' in tests for speed Co-authored-by: Michael Deceglie <[email protected]> * Miscellaneous documentation fixes (#287) * bump sphinx_rtd_theme version * fix broken link * sphinx deprecation warning * use intersphinx for pvlib functions * more intersphinx * notebook typos * update various copyrights * Bump notebook from 6.1.5 to 6.4.1 in /docs Bumps [notebook](https://github.com/jupyter/jupyterhub) from 6.1.5 to 6.4.1. - [Release notes](https://github.com/jupyter/jupyterhub/releases) - [Changelog](https://github.com/jupyterhub/jupyterhub/blob/main/CHECKLIST-Release.md) - [Commits](https://github.com/jupyter/jupyterhub/commits) --- updated-dependencies: - dependency-name: notebook dependency-type: direct:production ... Signed-off-by: dependabot[bot] <[email protected]> * Added new geometric clipping filter + unit test. (#200) * Added new geometric clipping filter + unit test. * Build unit tests + update __init__.py file * Updated changelog, API.rst and index.rst to reflect newly added clipping function. * Updated filter logic. * Added experimentally derived equation for handling relation between data sampling frequency and derivative threshold cutoff. Set as a default parameter, can be overridden by the user. * Updates to logic for filter for anomaly handling. * Added function for generating interactive graphs for tuning the clipping filter. Uses plotly to generate. * Instead of omitting outliers outright, set all outliers (high and low) to 0 automatically. * Pulled the function for running the clipping filter out of the plotly function. * Added plotly to requirements.txt. * Added plotly to setp.py file. * Built the unit tests for the plotly functionality (clipping filter plotting) * Added line for running the geometric clipping filter in the ipynb notebook. * Added the tune_clip_filter_plot to the initialization statement (debugging the Travic CI build failure) * Debugging for travis CI * Debugged the unit tests for the plots per @kanderso 's recommendations * Retrying plotting builds... * Added functions for logic-based and XGBoost clipping filters. * Added the Xgboost model in the new /models folder. * Added models folder + xgboost model. * Edits to the xgboost methodology * Refactoring of logic-based method (vectorized looping). * Added scikitlearn and joblib packages as installs. * Added xgboost package as a requirement * Bug fixing for travis ci build. * move changelog entry to pending * put back lost comma * added models folder to MANIFEST file. * Updated code to fit pep8 format. * Removed comma * Changed unit test script for plotting to logic_clip_filter from geometric_clip_filter. * Fixed pep8 formatting for the unit test scripts. * Fixed pep8 formatting per @kanderso's recommendations. * Fixed pep8 issues for the SRR method. * Updated initialization script. * Whitespace removal initialization script. * Updated api.rst with the two new clipping filters. * Fixed the xgboost model load. * Added min download requirements. * Switched to pytest on the filtering unit tests. * Formatting pep8 * Fixed pep8 errors * Updated the model path to eliminate filenotfound error. * created model path. * Fixing the file path. * Adjusted file path. * Fixing whitespace issue. * Adjusted the model path...again. * Model path fix again. * Fixing directory. * Refactored to combine duplicate code. * More refactoring on methods. * Fixed test script. * Updated the script to handle older package versions. * Updates based on @kanderso-nrel's code review. * Fixed unit tests to properly reference pytest fixtures. * Fixed the clipping filter outputs to only include the boolean series. * Debugging the series naming conventions for the clipping filters using actual fleets test cases. * Added new master wrapper function for running the clipping filter + associated unit test. * Added quantile_clip_filter to initialization script. * Updated plotting unit test. * Update to plotting unit tests. * Debugging xgboost model path. * Testing model path output for unit tests. * Updated model path again? * Added Value Error unit test for incorrect kwargs passed into the master clip_filter function. * Updating the deprecation warning per @mdeceglie's suggestion on PR. Made an official DeprecationWarning. Co-authored-by: Michael Deceglie <[email protected]> * Updates to include numbers package. * Updated comments for only handling AC power, per @mdeceglie's suggestion. We've used the filters on energy in the fleets pipeline, but it hasn't been rigorously tested, so let's leave it with AC power only. * Updates per @mdeceglie's review. * Troubleshooting model load for unit tests. * Fixing model import * Changed joblib version for importing model... * Updated min xgboost version. * Switched out model to update joblib version. * Updated to include scikit learn in package installs (debug per @kandersonrel's recommendation * Update to unit tests. * updated unit test again. * updates to xgboost method to handle missing time series rows (automatically not set as clipping. * Updated to 'rolling_range' from rolling derivative. * Debug unit tests * Updated to single axis tracking, per comment #200 (comment) * Unit tested exceptions in logic to up coverage * Added unit tests to increase coverage. * Updated the filter names, per Mike's request. * Updating to fit pep8 standards. * Updated the warning thrown for unit test. * Renamed plot function in init script. * Unit test for one minute intervals * Added 1 min interval coverage for XGBoost filter unit test. * Updated pytest fixture name. * Added unit tests for handling variable sampling frequency. * Updated function to handle unit tests (switched functions). * Unit test fixes. * Updated model. * Flake8 compliance * Flake8 compliance in plotting.py * Update plotting.py * Updated seconds to minutes for xgboost. * Updated the plotting coloring * Updated the unit tests based on filter updates. * Updated filters. * Update clipping filters. * Updated clipping filters + tested on the test set. * Added a warning that the clipping filters are still under development, per @mdeceglie's recommendation. * Fixing flake8 issues. * Update flake8> * More flake8 * update unit tests for new code updates * Update to unit tests for clip_filter wrapper * Update to unit tests. * Update to unit tests. * Unit tests. * Unit test. * Unit test * Unit tests * unit test debugging. * more debug * Changed dataframe to series for return in logic based clipping filter function. * Debugging datframe to series conversion. * More debugging * Additional debugging to match Matt's original filter. * Update filtering * Updated both filters based on rigorous testing. * Update xgb filter * Update to analysis chains based on push to dev last month. * updated numpy versioning to stop erroring * numpy fix * updated pandas to not get is_element error * Updated clipping threshold method for both clipping methods. * Updated jupyter notebook with new filters. * Update the python notebook for Trend Analysis. * doc string default adjustment * logic filter docstring update * update warnings Makes them more similar to those raised by other modules * Updated if-else statement to make it more concise. * Update examples of new plotting and clipping functions in the notebooks * Fixed interpolation issue for randomly sampled data for the xgboost method. * updated matt's code to handle irregular time intervals. * updated logic filter. * fix formatting issue. * Fix docstring overrides * Changed nearest to ffill for reindex. * Fixed my unit test file * Fixed the 0 on the docstring, per @kanderso's rec * Update the power_ac variable to signal, per @mdeceglie's request. * Removed trailing whitespace. * Update the scripts to handle all of the docstring issues. * Reverted naming conventions to power_ac from signal on filtering, updated to 'signal' in plotting. * tune_filter_plot docstring edit * docstring clean-up * address remaining items from review * changelog clean-up * unrestrict pandas version * Final updates from Matt on the logic-based filter. * changed from value error to index error for scrambled index on unit test. * update number of warnings thrown. * remove brackets for fixture function call in unit tests. * Updated unit test time series. * updated required min pandas installation (to calculate resample.quantile--from pandas 0.24.0 * Dropped back down min pandas version and updated +tested pd.Grouper method for pandas daily resampling with quantile. * removed brackets from unit test. * Made updates to the unit tests + doc strings per @mdeceglie's recs. * Updated the jupyter notebooks to handle the new clipping filters. Co-authored-by: Kirsten Perry <[email protected]> Co-authored-by: kperry2215 <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> Co-authored-by: Michael Deceglie <[email protected]> Co-authored-by: cdeline <[email protected]> Co-authored-by: Michael Deceglie <[email protected]> * update tornado version in notebook_requirements.txt * add helpful hint about xgboost package * fix code style * further notebook requirements update * final notebook run * Changelog updates * gotta have the :func: * Apply suggestions from code review Co-authored-by: Kevin Anderson <[email protected]> * review changes to 2.1.0 changelog * Recommit plotly plots in example * Add TrendAnalysis integration to PR template * add and apply requires_pvlib_below_090 pytest marker * bump pvlib requirement from <0.9.0 to <0.10.0 * bump pvlib min to 0.9.0; remove tables * resolve requirements-min scipy conflict * remove unnecessary [doc] requirements * set minimum pvlib back to 0.7.0 but still leave out tables except for requirements-min.txt * add warnings to sapm docstrings * changelog * more changelog * change log tables update * Update to include the DOI * Updated some of the doc strings for the clipping filters. * sort requirements * update pyzmq version * release date Co-authored-by: cdeline <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> Co-authored-by: Mark Mikofski <[email protected]> Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com> Co-authored-by: Kirsten Perry <[email protected]> Co-authored-by: Kirsten Perry <[email protected]> Co-authored-by: kperry2215 <[email protected]>
* Model chains (#117) * Add normalized_filter() function to replace the mannual filter in example * Initial working system analysis class * system analysis version that reproduces notebook results Works for both sensor and clearsky workflows * Improve underlying analysis These improvements slightly change the clearsky results relative to the existing version of the notebook. * Allow poa, temperature, and temperature_coefficient to be None This leaves room for BYO modeled PV perofmrance in the future * Add system_analysis to rdtools namespace * Basic example of system_analysis() use * Update degradation_and_soiling_example.ipynb 1) Use apparent zenith in irradiance calculations instead of zenith 2) Apply clearsky filter based on poa irradiance rather than insolation 3) Include ground diffuse in irradiance transposition calculations * Update system_analysis_example notebook Update notes and change initial poa calculation to include ground diffuse * Add a plotting module * Update notebook to use plotting module * Add plotting methods * update system_analysis example notebook * add docstrings * Delete model chain dev notes * add matplotlib to setup.py and update requirements * change matplotlib version * Move docstring to class * renormalization bug fix * Update temperature input interface (Also fix merge bug in plotting) * update docstring for new temperature interface * Remove __init__ docstring * update class name to CamelCase * update kwarg explanatations in docstrings * remove model parameter from calc_clearsky_poa() It is still addressable through kwargs passed to pvlib * Update SystemAnalysis_example.ipynb * Reformat dosctrings to numpy style * command style docstrings * Remove duplicate line * Update plotting docstrings to numpy style * Format normalized_filter docstring according to numpy style Other docstrings in this module have been updated in #125 * Add an ad hoc filter example to the notebook * Fixes system_analysis bug #132 when pv_nameplate is passed into syste… (#133) * Fixes system_analysis bug #132 when pv_nameplate is passed into system_analysis object. * typo fix Co-Authored-By: Kevin Anderson <[email protected]> * add bins parameter to plotting.degradation_summary_plot from #132 (cherry picked from commit efcbe2e) # Conflicts: # rdtools/plotting.py * plotting bug fix * Drop py2.7 and add 3.7 and 3.8 to testing (#135) * Drop 2.7 and add 3.7 and 3.8 to testing, update docs. * creating DatetimeIndex directly is deprecated, switch to pd.date_range * require pandas < 1.0.0 * bump requirements.txt numpy to 1.17.3 for testing on py3.8 * more requirements.txt updates for py3.8 wheel availability * Update v2.0.0.rst * add matplotlib to requirements * matplotlib 3.1 * matplotlib * merge pytests and jupyter example * PVLib > 0.7 changes to cell_temp calculation * Modelchain pytests (#196) * pytests for system_analysis. coverage: 91%. * rename system_analysis.py to analysis.py. Rename class to RdAnalysis. Update pvwatts_kws to match Master updates * Allow temp_model_params to either be string or dict with 'a','b', 'deltaT' keys * update calc_cell_temperature for pvlib > 0.6.3, use energy_normalized in normalize_with_pvwatts * Warn if temp coefficient not passed into normalize_with_Pvwatts instead of exit with error. * Add tables=3.6.1 to requirements.txt to allow clearsky analysis * add tables to setup.py since it appears to be a required pvlib for the clearsky workflow and not installed by default. * Add RdAnalysis notebook for pvdaq4 system * add max_timedelta=15T and clearsky poa calculation update to pvdaq4 standard notebook example * Sphinx release notes for 2.1.0 updated and API update Co-authored-by: Michael Deceglie <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> * Update tests, include tables in setup.py * suppress import warnings for soiling module. * Change warning suppression from warnings.resetwarnings to with warnings.catch_warnings(). Re-run notebooks * Model chains exp energy (#232) * enable normalize_with_expected_energy. * Update RdAnalysis_example.ipynb with manually defined power_expected option. * Add post-filter error check for < 2 yrs data per kanderson * Remove error message for no thermal model if power_expected is passed in. * remove tcell_filter from filter list if power_expected is passed in but not cell_temperature * pep8 compliance * more robust frequency check * shorten long lines * Model chains set clearsky (#233) * Move CS inputs to new set_clearsky function: pvlib_location ,pv_tilt, pv_azimuth, clearsky_poa, clearsky temp, albedo * Explicit error message if set_clearsky not run prior to clearsky_analysis. * remove Py2.7 check in block 3 of RdAnalysis_example.ipynb * boost analysis.py test coverage to 94% * add pv_energy pytest case. Change to ValueError rather than basic Exception when set_clearsky hasn't been run. Co-authored-by: Kevin Anderson <[email protected]> * improve index equality conditional * pep8 cleanup * change dict key syntax * Clarify behavior when pv_nameplate is omitted * Useful errors for plotting methods * update requreiments for tables * reduce minimum version of tables * Delete RdAnalysis_example.ipynb * Remove max_timedelta parameter use in PVDAQ example * Move sun position calculation to clearsky section of example This brings the clearsky results into better allignement with the objected oriented example, now sun position is calculated after interpolation on both * Update chage log version number * Allow warning for experimental modules * pep8 analysis_test.py * Change module and class names * Update example with new module/class name * Fix outdated ref to system_analysis * Update api.rst with analysis chains module name * Fix changelog underline length * update index.rst with TrendAnalysis info * poa -> poa_global * cell_temperature -> temperature_cell * ambient_temperature->temperature_ambient * temperature_coefficient->gamma_pdc * temperature_model docstring * pv_nameplate->power_dc_rated * clearsky_poa->poa_global_clearsky * clearsky_temperature_cell->temperature_cell_clearsky * clearsky_temperature_ambient->temperature_ambient_clearsky * Align yoy and srr parameters with functional API * Use `case` in plotting methods * Change notebook kernel * weakly privatize some methods * Update rdtools/analysis_chains.py Co-authored-by: Kevin Anderson <[email protected]> * Interpolate windspeed * Update rdtools/analysis_chains.py Co-authored-by: Kevin Anderson <[email protected]> * implement review suggestions * more TrendAnalysis tests to improve coverage * cleanup * Fix copy/paste error in notebook * change _calc_cell_temeprature parameter order * More elegant error if filtering results in empty series * Changelog consolidation * change log update Co-authored-by: cdeline <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> * add beta version to change log * add missing parenthesis * add TrendAnalysis notebook to gallery * good merging gone bad * fix analysis_chains_test.py * pin numexpr to 2.7.1 in requirements-min.txt * Update changelog with beta release * Fix typo in TrendAnalysis docstring (#264) * parameters -> params * changelog * Consecutive cleaning logic (#199) * Remove consecutive cleaning filter * Change day_scale default to 13 and raise warning for even values * Update soiling tests * Run notebooks * Update changelog * changelog adjustment * Update rdtools/soiling.py Co-authored-by: Kevin Anderson <[email protected]> * keep invalid intervals at beginning and end * Revert "keep invalid intervals at beginning and end" This reverts commit b3f5efc. * keep invalid intervals at beginning abd end This revision properly hanldes the trim option * Handle consecutive invalid intervals correctly for random_clean * Remove outdated comment * Adjust trend_analysis soiling test * Add a warning for >20% invalid data and random cleaning assumptions * Run notebooks degradation_and_soiling_example.ipynb exhibits a small change in the clearsky degradation results attributed to changes in random number generator state from soiling workflow changes * patch test * Add outlier factor to adjust cleaning detection sensitivity * fix flake8 errors * Add a test for outlier_factor * add outlier_factor to change log * add #234 to change log * Add invalid interval retention at start and end to change log * Clean up review suggestions * add references to #272 * fix line length * parametrize some tests * update changelog * Update the notebooks Only some warnings changed slightly * change min_interval_length default from 2 to 7 * fix line length * Add Matt to the change log contributors Co-authored-by: Kevin Anderson <[email protected]> * Issue #120 Revise NaN pixel handling in clearsky_temperature.py (#274) * Revise NaN pixel handling in clearsky_temperature.py. Raise specific warning. Fixes #120 * Changelog update * rewrite cs tamb test in pytest style * add test for not-on-land Co-authored-by: Kevin Anderson <[email protected]> * Test suite warning clean-up (#273) * suppress experimental module warnings * close figs to avoid pyplot warning * use odd day_scale value * don't use deprecated check_less_precise * prevent pandas warning about average of non-numeric types * soiling warnings * interpolation warning * add notes * cleaner suppression for soiling warning * revert unnecessary changes * units cleanup (#276) * Update requirements files (#275) * bump numpy version to handle windows compat issue * bump pygments and jinja2 using dependabot reccs * add missing indirect dependencies to requirements.txt * add missing indirect dependencies to notebook_requirements.txt * changelog * partially un-bump numpy * update nbsphinx version in setup.py spatialaudio/nbsphinx#563 Co-authored-by: Michael Deceglie <[email protected]> * add intersphinx so that type links work (#258) * add intersphinx so that type links work [Sphinx intersphinx](https://www.sphinx-doc.org/en/master/usage/extensions/intersphinx.html) is not added by default, it must be enabled and configured. Added links for: * python * numpy * pandas * scipy this will create links for types like `float`, `dict`, _etc_. and `pandas.DataFrame`, `numpy.ndarray`, _etc_. * remove trailing single quote in doc confs Co-authored-by: Michael Deceglie <[email protected]> * add pvlib intersphinx * addresses #241 * add mpl intersphinx url * fix up docstring types * more type fixes * python 3.8 -> python 3 * changelog * make soiling docstrings more consistent * fix indents in soiling docstrings * fix unexpected indent * Get the bulleted lists working in sphinx * attempt to get tuple type link working * Attempt to get type links working on TrendAnalysis * Fix trailing whitespace * type link adjustments * change from datetime to pandas timedelta in TrenAnalysis docs * Couple more link type adjustments * add type aliases * remove numpy.array Co-authored-by: Michael Deceglie <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> Co-authored-by: Michael Deceglie <[email protected]> * Store filter components on TrendAnalysis (#263) * add attributes * test * changelog * unrelated linting * bug fixes * remove unnecessary default filter, test * fix up index union funny business * preliminary fix for #266 * add test to cover new warnings * improve warning messages * expand tests * delete extra blank line Co-authored-by: Michael Deceglie <[email protected]> Co-authored-by: Michael Deceglie <[email protected]> * Loosen soiling input check to allow implicit daily index (#279) * remove empty line in pending.rst * use pd.infer_freq instead of checking index.freq directly * add test * add test for other warnings/errors too, for coverage * Adjust trend analysis interpolation behavior (#278) * Interpolate things onto pv index * add test for interpolation behavior * Update rdtools/test/analysis_chains_test.py Co-authored-by: Kevin Anderson <[email protected]> * Test set_clearsky interpolation * consolidate dummy series in test Co-authored-by: Kevin Anderson <[email protected]> * Plotting function allows data gap visualization (#282) * add 'usage_of_points' calculation to degradation.py. Seems to work ok now.. * usage of points pytest * add 'usage_of_points' to rd_result output * plotting function update add 'detailed' option, = False by default * PEP8 updates * streamline color selector with map instead of apply * add detailed=True kwarg to test_degradation_summary_plots_kwargs * Update plotting docstring. Add changelog entry. Co-authored-by: Kevin Anderson <[email protected]> Co-authored-by: Michael Deceglie <[email protected]> * Update TrendAnalysis notebook to avoid filter index mismatch warning * Adjust TrendAnalysis interpolations for index mismatch (#285) * dedent non-pv inputs * dedent clearsky inputs as well * add basic test * Use interval averages for clear-sky irradiance modeling (#281) * prelim 1-min+aggregate fix * update test asserts * add manual high-res sim+aggregation to DKASC notebook * set first value to nan * update from review: backfill change * add solar_position_method kwarg to TrendAnalysis.set_clearsky * maybe one day I'll learn to test changes prior to pushing * explicitly set default method=nrel_numpy * add test for solar_position_method kwarg using pytest-mock * use method='ephemeris' in tests for speed Co-authored-by: Michael Deceglie <[email protected]> * Miscellaneous documentation fixes (#287) * bump sphinx_rtd_theme version * fix broken link * sphinx deprecation warning * use intersphinx for pvlib functions * more intersphinx * notebook typos * update various copyrights * Added new geometric clipping filter + unit test. (#200) * Added new geometric clipping filter + unit test. * Build unit tests + update __init__.py file * Updated changelog, API.rst and index.rst to reflect newly added clipping function. * Updated filter logic. * Added experimentally derived equation for handling relation between data sampling frequency and derivative threshold cutoff. Set as a default parameter, can be overridden by the user. * Updates to logic for filter for anomaly handling. * Added function for generating interactive graphs for tuning the clipping filter. Uses plotly to generate. * Instead of omitting outliers outright, set all outliers (high and low) to 0 automatically. * Pulled the function for running the clipping filter out of the plotly function. * Added plotly to requirements.txt. * Added plotly to setp.py file. * Built the unit tests for the plotly functionality (clipping filter plotting) * Added line for running the geometric clipping filter in the ipynb notebook. * Added the tune_clip_filter_plot to the initialization statement (debugging the Travic CI build failure) * Debugging for travis CI * Debugged the unit tests for the plots per @kanderso 's recommendations * Retrying plotting builds... * Added functions for logic-based and XGBoost clipping filters. * Added the Xgboost model in the new /models folder. * Added models folder + xgboost model. * Edits to the xgboost methodology * Refactoring of logic-based method (vectorized looping). * Added scikitlearn and joblib packages as installs. * Added xgboost package as a requirement * Bug fixing for travis ci build. * move changelog entry to pending * put back lost comma * added models folder to MANIFEST file. * Updated code to fit pep8 format. * Removed comma * Changed unit test script for plotting to logic_clip_filter from geometric_clip_filter. * Fixed pep8 formatting for the unit test scripts. * Fixed pep8 formatting per @kanderso's recommendations. * Fixed pep8 issues for the SRR method. * Updated initialization script. * Whitespace removal initialization script. * Updated api.rst with the two new clipping filters. * Fixed the xgboost model load. * Added min download requirements. * Switched to pytest on the filtering unit tests. * Formatting pep8 * Fixed pep8 errors * Updated the model path to eliminate filenotfound error. * created model path. * Fixing the file path. * Adjusted file path. * Fixing whitespace issue. * Adjusted the model path...again. * Model path fix again. * Fixing directory. * Refactored to combine duplicate code. * More refactoring on methods. * Fixed test script. * Updated the script to handle older package versions. * Updates based on @kanderso-nrel's code review. * Fixed unit tests to properly reference pytest fixtures. * Fixed the clipping filter outputs to only include the boolean series. * Debugging the series naming conventions for the clipping filters using actual fleets test cases. * Added new master wrapper function for running the clipping filter + associated unit test. * Added quantile_clip_filter to initialization script. * Updated plotting unit test. * Update to plotting unit tests. * Debugging xgboost model path. * Testing model path output for unit tests. * Updated model path again? * Added Value Error unit test for incorrect kwargs passed into the master clip_filter function. * Updating the deprecation warning per @mdeceglie's suggestion on PR. Made an official DeprecationWarning. Co-authored-by: Michael Deceglie <[email protected]> * Updates to include numbers package. * Updated comments for only handling AC power, per @mdeceglie's suggestion. We've used the filters on energy in the fleets pipeline, but it hasn't been rigorously tested, so let's leave it with AC power only. * Updates per @mdeceglie's review. * Troubleshooting model load for unit tests. * Fixing model import * Changed joblib version for importing model... * Updated min xgboost version. * Switched out model to update joblib version. * Updated to include scikit learn in package installs (debug per @kandersonrel's recommendation * Update to unit tests. * updated unit test again. * updates to xgboost method to handle missing time series rows (automatically not set as clipping. * Updated to 'rolling_range' from rolling derivative. * Debug unit tests * Updated to single axis tracking, per comment #200 (comment) * Unit tested exceptions in logic to up coverage * Added unit tests to increase coverage. * Updated the filter names, per Mike's request. * Updating to fit pep8 standards. * Updated the warning thrown for unit test. * Renamed plot function in init script. * Unit test for one minute intervals * Added 1 min interval coverage for XGBoost filter unit test. * Updated pytest fixture name. * Added unit tests for handling variable sampling frequency. * Updated function to handle unit tests (switched functions). * Unit test fixes. * Updated model. * Flake8 compliance * Flake8 compliance in plotting.py * Update plotting.py * Updated seconds to minutes for xgboost. * Updated the plotting coloring * Updated the unit tests based on filter updates. * Updated filters. * Update clipping filters. * Updated clipping filters + tested on the test set. * Added a warning that the clipping filters are still under development, per @mdeceglie's recommendation. * Fixing flake8 issues. * Update flake8> * More flake8 * update unit tests for new code updates * Update to unit tests for clip_filter wrapper * Update to unit tests. * Update to unit tests. * Unit tests. * Unit test. * Unit test * Unit tests * unit test debugging. * more debug * Changed dataframe to series for return in logic based clipping filter function. * Debugging datframe to series conversion. * More debugging * Additional debugging to match Matt's original filter. * Update filtering * Updated both filters based on rigorous testing. * Update xgb filter * Update to analysis chains based on push to dev last month. * updated numpy versioning to stop erroring * numpy fix * updated pandas to not get is_element error * Updated clipping threshold method for both clipping methods. * Updated jupyter notebook with new filters. * Update the python notebook for Trend Analysis. * doc string default adjustment * logic filter docstring update * update warnings Makes them more similar to those raised by other modules * Updated if-else statement to make it more concise. * Update examples of new plotting and clipping functions in the notebooks * Fixed interpolation issue for randomly sampled data for the xgboost method. * updated matt's code to handle irregular time intervals. * updated logic filter. * fix formatting issue. * Fix docstring overrides * Changed nearest to ffill for reindex. * Fixed my unit test file * Fixed the 0 on the docstring, per @kanderso's rec * Update the power_ac variable to signal, per @mdeceglie's request. * Removed trailing whitespace. * Update the scripts to handle all of the docstring issues. * Reverted naming conventions to power_ac from signal on filtering, updated to 'signal' in plotting. * tune_filter_plot docstring edit * docstring clean-up * address remaining items from review * changelog clean-up * unrestrict pandas version * Final updates from Matt on the logic-based filter. * changed from value error to index error for scrambled index on unit test. * update number of warnings thrown. * remove brackets for fixture function call in unit tests. * Updated unit test time series. * updated required min pandas installation (to calculate resample.quantile--from pandas 0.24.0 * Dropped back down min pandas version and updated +tested pd.Grouper method for pandas daily resampling with quantile. * removed brackets from unit test. * Made updates to the unit tests + doc strings per @mdeceglie's recs. * Updated the jupyter notebooks to handle the new clipping filters. Co-authored-by: Kirsten Perry <[email protected]> Co-authored-by: kperry2215 <[email protected]> Co-authored-by: Kevin Anderson <[email protected]> Co-authored-by: Michael Deceglie <[email protected]> Co-authored-by: cdeline <[email protected]> Co-authored-by: Michael Deceglie <[email protected]> * add 3.10 to pytest matrix * quote versions so 3.10 isn't interpreted as 3.1 * don't use requirements-min on py3.10 * update most of requirements.txt for py3.10 * drop 3.6 from test matrix, use requirements-min with 3.7 instead * bump requirements-min to versions that have py37-compatible wheels * bump tables version again * mirror new minimum dep versions in setup.py * update various references to supporting python versions * create v2.1.2 changelog file * create v2.1.3 changelog * bump scikit-learn to 1.0.2 in requirements.txt * more changelog * use more robust warning testing * tweaks * switch to pure pyplot calls * rerun availability nb * changelog * add testing section to changelog * fix erroneous comment Co-authored-by: Michael Deceglie <[email protected]> Co-authored-by: cdeline <[email protected]> Co-authored-by: Michael Deceglie <[email protected]> Co-authored-by: Mark Mikofski <[email protected]> Co-authored-by: Kirsten Perry <[email protected]> Co-authored-by: Kirsten Perry <[email protected]> Co-authored-by: kperry2215 <[email protected]>
__init__.py