We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
全表扫描对 Server 的影响
假设执行以下语句进行全表扫描:
mysql -h$host -P$port -u$user -p$pwd -e "select * from db1.t" > $target_file
取数据和发数据的流程是这样的:
如果故意让客户端不去读 socket receive buffer 中的内容,然后在服务端 show processlist 可以看到: State 值会处于 Sending to client 状态,表示服务器端的网络栈写满了。 真实场景中,如果客户端使用 -quick 参数,MySQL 会使用 mysql_use_result 方式,而这个方法是读一行处理一行,如果一个业务的逻辑比较复杂,每读一行数据都处理的很慢,就会导致客户端要过很久才会去取下一行的数据,就会出现上述的情况 因此,对于正常的线上业务来说,如果一个查询的返回结果不会很多的话,建议使用 mysql_store_result 接口,直接把查询结果保存到本地内存 如果在 MySQL 中看到多个线程都处于 Sending to client 状态,就应该去优化查询结果,并评估返回结果是否过多。如果要减少处于这个状态的线程,可以将 net_buffer_length 参数调大
与 Sending to client 长的类似的状态是 Sending data,Sending data 并不一定是指正在发送数据,也可能是处于执行器过程中的任意阶段。 实际上,一个查询语句的变化状态是这样的(略去了其他无关状态):
全表扫描对 InnoDB 的影响
InnoDB 内存的数据页是在 Buffer Pool(BP)中管理的,在 WAL 里 Buffer Pool 起到了加速更新的作用。其实,Buffer Pool 也有加速查询的作用。 这里涉及到一个问题:由于有 WAL 机制,当事务提交的时候,磁盘上的数据页是旧的,如果这时候马上有一个查询要读这个数据页,是不是要把 redo log 应用到数据页呢? 答案是不需要,因为这时候内存数据页的结果是最新的,直接读内存页即可,所以说 Buffer Pool 有加速查询的作用
但是 Buffer Pool 对查询的加速效果依赖于内存命中率。可以在 show engine innodb status 结果中查看系统的当前的 BP 命中率(Buffer pool hit rate)。一般情况下,一个稳定的线上系统,要保证响应时间符合要求,内存命中率要在 99% 以上
InnoDB Buffer Pool 的大小由参数 innodb_buffer_pool_size 决定,一般建议设置成可用物理内存的 60%~80%
InnoDB 内存管理用的是最近最少使用(Last Recently Used,LRU)算法,不过对其进行了改进。因为原始的 LRU 算法在进行全表扫描时,会把 Buffer Pool 中的数据全部淘汰,存入扫描过程中访问到的数据,这会导致 Buffer Pool 的内存命中率下降,磁盘压力增加,SQL 语句响应变慢
在 InnoDB 实现上,按照 5:3 的比例把整个 LRU 链表分成了 young 区域和 old 区域,如下图: 图中 LRU_old 指向的是 old 区域的第一个位置,是整个链表的 5/8 处。 改进后的 LRU 算法执行流程如下:
The text was updated successfully, but these errors were encountered:
No branches or pull requests
全表扫描对 Server 的影响
假设执行以下语句进行全表扫描:
取数据和发数据的流程是这样的:
从图中可以知道:
所以内存是不会被打爆。
并且也可以知道,MySQL 是边读边发的,这也就意味着,如果客户端接收的慢,会导致 MySQL 服务端由于结果发送不出去,这个事务的执行时间会变长。
如果故意让客户端不去读 socket receive buffer 中的内容,然后在服务端 show processlist 可以看到:

State 值会处于 Sending to client 状态,表示服务器端的网络栈写满了。
真实场景中,如果客户端使用 -quick 参数,MySQL 会使用 mysql_use_result 方式,而这个方法是读一行处理一行,如果一个业务的逻辑比较复杂,每读一行数据都处理的很慢,就会导致客户端要过很久才会去取下一行的数据,就会出现上述的情况
因此,对于正常的线上业务来说,如果一个查询的返回结果不会很多的话,建议使用 mysql_store_result 接口,直接把查询结果保存到本地内存
如果在 MySQL 中看到多个线程都处于 Sending to client 状态,就应该去优化查询结果,并评估返回结果是否过多。如果要减少处于这个状态的线程,可以将 net_buffer_length 参数调大
与 Sending to client 长的类似的状态是 Sending data,Sending data 并不一定是指正在发送数据,也可能是处于执行器过程中的任意阶段。
实际上,一个查询语句的变化状态是这样的(略去了其他无关状态):
可以通过构造一个锁等待的场景,就能看到 Sending data 状态:
总的来说,Sending to client 状态表示一个线程处于等待客户端接收结果的状态,Sending data 状态表示正在执行
全表扫描对 InnoDB 的影响
InnoDB 内存的数据页是在 Buffer Pool(BP)中管理的,在 WAL 里 Buffer Pool 起到了加速更新的作用。其实,Buffer Pool 也有加速查询的作用。
这里涉及到一个问题:由于有 WAL 机制,当事务提交的时候,磁盘上的数据页是旧的,如果这时候马上有一个查询要读这个数据页,是不是要把 redo log 应用到数据页呢?
答案是不需要,因为这时候内存数据页的结果是最新的,直接读内存页即可,所以说 Buffer Pool 有加速查询的作用
但是 Buffer Pool 对查询的加速效果依赖于内存命中率。可以在 show engine innodb status 结果中查看系统的当前的 BP 命中率(Buffer pool hit rate)。一般情况下,一个稳定的线上系统,要保证响应时间符合要求,内存命中率要在 99% 以上
InnoDB Buffer Pool 的大小由参数 innodb_buffer_pool_size 决定,一般建议设置成可用物理内存的 60%~80%
InnoDB 内存管理用的是最近最少使用(Last Recently Used,LRU)算法,不过对其进行了改进。因为原始的 LRU 算法在进行全表扫描时,会把 Buffer Pool 中的数据全部淘汰,存入扫描过程中访问到的数据,这会导致 Buffer Pool 的内存命中率下降,磁盘压力增加,SQL 语句响应变慢
在 InnoDB 实现上,按照 5:3 的比例把整个 LRU 链表分成了 young 区域和 old 区域,如下图:
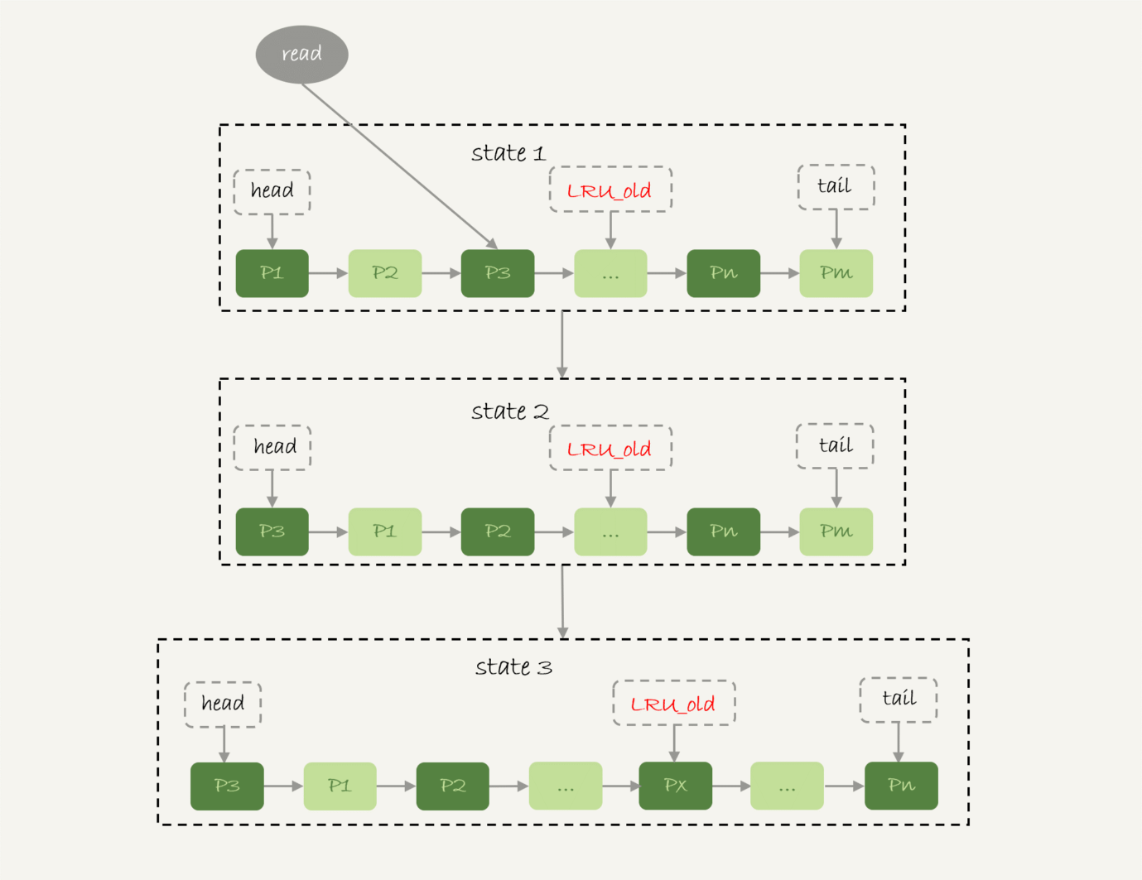
图中 LRU_old 指向的是 old 区域的第一个位置,是整个链表的 5/8 处。
改进后的 LRU 算法执行流程如下:
1 秒这个时间由参数 innodb_old_blocksZ_time 控制,默认为 1000,单位毫秒
The text was updated successfully, but these errors were encountered: