You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
可以看到,t1 分了两次放入 join_buffer,导致 t2 会被扫描 2 次,不过判断次数不会变
那这种情况下,怎么选择驱动表呢?
假设,驱动表的数据行数是 N,需要分 K 段才能完成算法流程,被驱动表的数据行数是 M 。
这里的 K 不是常数,N 越大 K 就会越大,因此把 K 表示为 λ*N,λ 的取值范围为 (0,1),所以在这个算法的执行过程中:
扫描行数是 N + λ * N * M
内存判断 N * M 次
显然,内存判断次数不受选择哪个表作为驱动表影响,而扫描行数在 M 和 N 大小确定的情况下,N 小一些,整个算式的结果会更小
当 N 固定的时候 K 受 join_buffer_size 的影响,join_buffer_size 越大,K 越小
什么叫做小表?
按照条件过滤后,参与 join 的各个字段的总数据量小的为小表
The text was updated successfully, but these errors were encountered:
我们用下面两个表来说明 join 是怎么执行的,然后来回答这个问题:
Index Nested-Loop Join
这里使用 straight join 让 MySQL 使用固定的连接方式执行查询,便于分析执行过程中的性能问题。

在这个语句里,t1 是驱动表,t2 是被驱动表,现在我们看下 explain 的结果:
可以看到,被驱动表 t2 的字段 a 上有索引,并且 join 过程中使用到了该索引,因此这个语句的执行流程如下:
在形式上,这个过程和我们写程序时的嵌套查询类型,并且可以用上被驱动表的索引,称之为 Index Nested-Loop Join,简称 NLJ,对应流程图如下:
在这个流程里:
那如果不使用 join,执行流程是怎么样的?
不使用 join ,就执行用单表查询,执行流程如下:
可以看到,查询过程中也是扫描了 200 行, 但总共执行了 101 条语句,比使用 join 多了 100 次交互,而且客户端还要自己拼接 SQL 语句和结果,显然不如使用 join
那如果使用 join,怎么选择驱动表呢?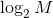 ,所以在被驱动表上查一行的时间复杂度是
,所以在被驱动表上查一行的时间复杂度是 

在这个 join 语句的执行过程中,驱动表走的是全表扫描,被驱动表走的是树搜索。
假设被驱动表的行数是 M,每次在被驱动表查一行数据,首先搜索索引 a,再搜索主键索引。每次搜索一棵树近似复杂度为
假设驱动板的行数是 N,执行过程就要扫描驱动表 N 行,然后对于每一行,到被驱动表上匹配一次,因此整个执行过程,近似复杂度是
显然,N 对复杂度的影响更大,因此应该让小表来做驱动表
通过上面的分析可以知道,在可以使用被驱动表索引的情况下:
Simple Nested-Loop Join
如果被驱动表用不上索引的执行流程会怎么样呢?我们先修改下 SQL :
由于 t2 的字段 b 没有索引,因此每次去 t2 去匹配的时候,就要做一次全表扫描,这个算法叫做 Simple Nested-Loop Join
这样算来,这个 SQL 请求需要扫描表 t2 100次,总共扫描 100 * 1000 行,不过 MySQL 也没有使用这个算法,而是使用了 Block Nested-Loop Join,简称 BNL
Block Nested-Loop Join
该算法流程如下:
执行流程图如下:
语句的 explain 结果如下:
在这个过程中,对 t1 和 t2 都做了一次全表扫描,总的扫描行数为 1100。由于 join_buffer 是以无序数组的方式组织的,因此对 t2 的每一行都要做 100 次判断,总共需要在内存中做 100 * 1000 次判断
从时间复杂度上来说 Simple Nested-Loop Join 和 Block Nested-Loop Join 一致,但是 BNJ 是内存操作,所以性能更好
那么这种情况下应该选择哪个表作为驱动表呢?
假设小表的行数是 N,大表的行数是 M,那么:
可以看到哪个表作为驱动表,执行耗时都是一样的。但是大表会受到 join_buffer 的影响
join_buffer 的大小由参数 join_buffer_size 设定,默认为 256K,如果放不下 t1 的所有数据,就分段放。假设 t1 表到 88 行之后,join_buffer 就满了,执行过程如下:
流程图如下:
步骤 4 和 5 表示清空 join_buffer 再复用
可以看到,t1 分了两次放入 join_buffer,导致 t2 会被扫描 2 次,不过判断次数不会变
那这种情况下,怎么选择驱动表呢?
假设,驱动表的数据行数是 N,需要分 K 段才能完成算法流程,被驱动表的数据行数是 M 。
这里的 K 不是常数,N 越大 K 就会越大,因此把 K 表示为 λ*N,λ 的取值范围为 (0,1),所以在这个算法的执行过程中:
显然,内存判断次数不受选择哪个表作为驱动表影响,而扫描行数在 M 和 N 大小确定的情况下,N 小一些,整个算式的结果会更小
当 N 固定的时候 K 受 join_buffer_size 的影响,join_buffer_size 越大,K 越小
什么叫做小表?
按照条件过滤后,参与 join 的各个字段的总数据量小的为小表
The text was updated successfully, but these errors were encountered: