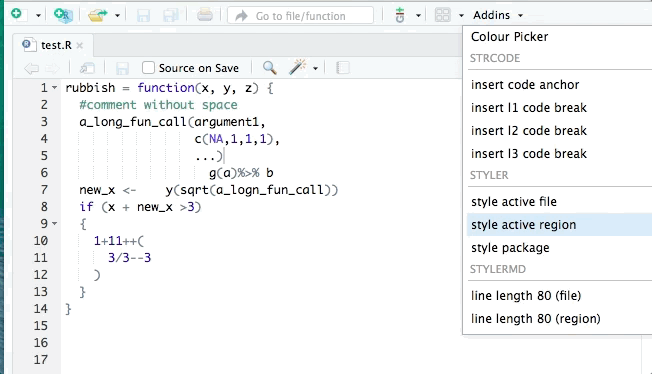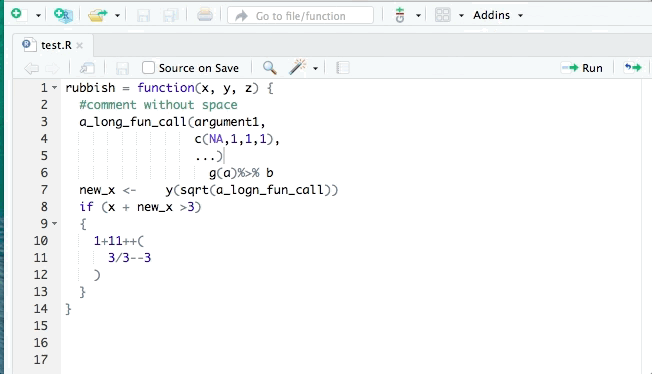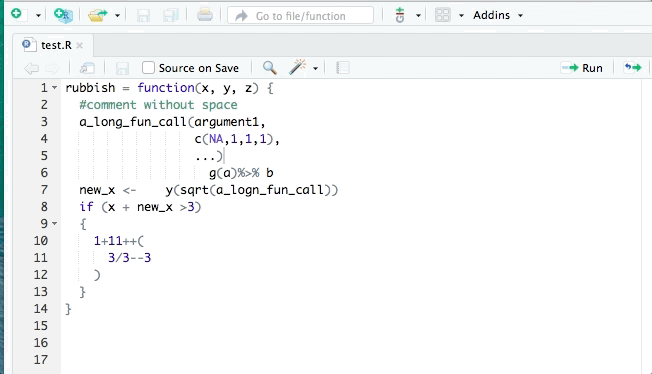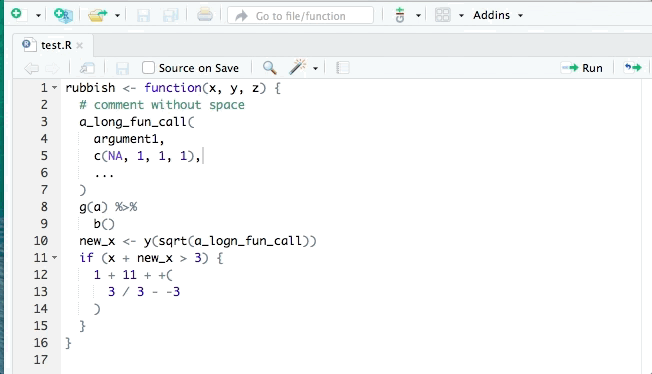
+
library("dplyr")
+library("purrr")
+pkgload::load_all()
+
This vignette builds on the vignette “Data Structures” and discusses how to go forward with the nested structure of the parse data. In order to compute the white space information in a nested data structure, we need a recursion. We use a visitor approach to separate the algorithm (computing white space information) from the object (nested) data structure. The function create_filler() can then be used to add white space information on every level of nesting within the nested parse data if applied in combination with the visitor. visitor() takes a object to operate on and a list of functions. Each function is applied at the current level of nesting before the next level of nesting is entered.
+
+
## function(pd_nested, funs) {
+## if (is.null(pd_nested)) return()
+## pd_transformed <- visit_one(pd_nested, funs)
+##
+## pd_transformed$child <- map(pd_transformed$child, pre_visit, funs = funs)
+## pd_transformed
+## }
+## <environment: namespace:styler>
+
+
## function(pd_flat, funs) {
+## reduce(funs, function(x, fun) fun(x),
+## .init = pd_flat)
+## }
+## <environment: namespace:styler>
+
This comes with two advantages.
+
+- We don’t need a *_nested() version of every function we want to apply to the parse tables, in particular the rules in R/rules.R
+- We go through the whole structure only once (instead of every *_nested() function going through it once, which is more efficient in terms of speed.
+
+
create_filler() was adapted to also initialize indention and lag_newlines.
+
+
## function(pd_flat) {
+##
+## pd_flat$line3 <- lead(pd_flat$line1, default = tail(pd_flat$line2, 1))
+## pd_flat$col3 <- lead(pd_flat$col1, default = tail(pd_flat$col2, 1) + 1L)
+## pd_flat$newlines <- pd_flat$line3 - pd_flat$line2
+## pd_flat$lag_newlines <- lag(pd_flat$newlines, default = 0)
+## pd_flat$col2_nl <- if_else(pd_flat$newlines > 0L, 0L, pd_flat$col2)
+## pd_flat$spaces <- pd_flat$col3 - pd_flat$col2_nl - 1L
+## pd_flat$multi_line <- ifelse(pd_flat$terminal, FALSE, NA)
+##
+## ret <- pd_flat[, !(names(pd_flat) %in% c("line3", "col3", "col2_nl"))]
+##
+##
+## if (!("indent" %in% names(ret))) {
+## ret$indent <- 0
+## }
+##
+## if (any(ret$spaces < 0L)) {
+## stop("Invalid parse data")
+## }
+##
+## ret
+## }
+## <environment: namespace:styler>
+
code <- "a <- function(x) { if(x > 1) { 1+1 } else {x} }"
+pd_nested <- compute_parse_data_nested(code)
+pd_nested_enhanced <- pre_visit(pd_nested, c(create_filler))
+pd_nested_enhanced
+
## # A tibble: 1 x 19
+## line1 col1 line2 col2 id parent token terminal text short
+## <int> <int> <int> <int> <int> <int> <chr> <lgl> <chr> <chr>
+## 1 1 1 1 47 49 0 expr FALSE
+## # ... with 9 more variables: token_before <chr>, token_after <chr>,
+## # internal <lgl>, child <list>, newlines <int>, lag_newlines <dbl>,
+## # spaces <int>, multi_line <lgl>, indent <dbl>
+
As a next step, we need to find a way to serialize the nested tibble, or in other words, to transform it to its character vector representation. As a starting point, consider the function serialize that was introduced in the vignette “Data Structures”.
+
serialize <- function(x) {
+ out <- Map(
+ function(terminal, text, child) {
+ if (terminal)
+ text
+ else
+ serialize(child)
+ },
+ x$terminal, x$text, x$child
+ )
+ out
+}
+
+serialize(pd_nested) %>% unlist
+
## [1] "a" "<-" "function" "(" "x" ")"
+## [7] "{" "if" "(" "x" ">" "1"
+## [13] ")" "{" "1" "+" "1" "}"
+## [19] "else" "{" "x" "}" "}"
+
serialize can be combined with serialize_parse_data_flat. The latter pastes together the column “text” of a flat parse table by taking into account space and line break information, splits the string by line break and returns it.
+
serialize_parse_data_flat
+
## function(pd_flat) {
+## pd_flat %>%
+## summarize_(
+## text_ws = ~paste0(
+## text, newlines_and_spaces(newlines, spaces),
+## collapse = "")) %>%
+## .[["text_ws"]] %>%
+## strsplit("\\n", fixed = TRUE) %>%
+## .[[1L]]
+## }
+## <environment: namespace:styler>
+
However, things get a bit more complicated, mainly because line break and white space information is not only contained in the terminal tibbles of the nested parse data, but even before, as the following example shows.
+
pd_nested_enhanced$child[[1]]
+
## # A tibble: 3 x 19
+## line1 col1 line2 col2 id parent token terminal text short
+## <int> <int> <int> <int> <int> <int> <chr> <lgl> <chr> <chr>
+## 1 1 1 1 1 3 49 expr FALSE
+## 2 1 3 1 4 2 49 LEFT_ASSIGN TRUE <- <-
+## 3 1 6 1 47 48 49 expr FALSE
+## # ... with 9 more variables: token_before <chr>, token_after <chr>,
+## # internal <lgl>, child <list>, newlines <int>, lag_newlines <dbl>,
+## # spaces <int>, multi_line <lgl>, indent <dbl>
+
pd_nested_enhanced$child[[1]]$child[[1]]
+
## # A tibble: 1 x 19
+## line1 col1 line2 col2 id parent token terminal text short
+## <int> <int> <int> <int> <int> <int> <chr> <lgl> <chr> <chr>
+## 1 1 1 1 1 1 3 SYMBOL TRUE a a
+## # ... with 9 more variables: token_before <chr>, token_after <chr>,
+## # child <list>, internal <lgl>, newlines <int>, lag_newlines <dbl>,
+## # spaces <int>, multi_line <lgl>, indent <dbl>
+
After “a” in code, there is a space, but this information is not contained in the tibble where we find the terminal “a”. In general, we must add newlines and spaces values after we computed character vector representation of the expression. In our example: we know that there is a space after the non-terminal “a” by looking at pd_nested_enhanced$child[[1]]. Therefore, we need to add this space to the very last terminal within pd_nested_enhanced$child[[1]] before we collapse everything together.
+
serialize_parse_data_nested_helper
+
## function(pd_nested, pass_indent) {
+## out <- pmap(list(pd_nested$terminal, pd_nested$text, pd_nested$child,
+## pd_nested$spaces, pd_nested$lag_newlines, pd_nested$indent),
+## function(terminal, text, child, spaces, lag_newlines, indent) {
+## total_indent <- pass_indent + indent
+## preceding_linebreak <- if_else(lag_newlines > 0, 1, 0)
+## if (terminal) {
+## c(add_newlines(lag_newlines),
+## add_spaces(total_indent * preceding_linebreak),
+## text,
+## add_spaces(spaces))
+## } else {
+## c(add_newlines(lag_newlines),
+## add_spaces(total_indent * preceding_linebreak),
+## serialize_parse_data_nested_helper(child, total_indent),
+## add_spaces(spaces))
+## }
+## }
+## )
+## out
+## }
+## <environment: namespace:styler>
+
serialize_parse_data_nested
+
## function(pd_nested) {
+## out <- c(add_newlines(start_on_line(pd_nested) - 1),
+## serialize_parse_data_nested_helper(pd_nested, pass_indent = 0)) %>%
+## unlist() %>%
+## paste0(collapse = "") %>%
+## strsplit("\\n", fixed = TRUE) %>%
+## .[[1L]]
+## out
+## }
+## <environment: namespace:styler>
+
Before we are done, we need to add information regarding indention to the parse table. We can add indention after every line break that comes after a round bracket with indent_round(). And then serialize it.
+
pre_visit(pd_nested,
+ c(create_filler,
+ purrr::partial(indent_round, indent_by = 2)))
+
## # A tibble: 1 x 19
+## line1 col1 line2 col2 id parent token terminal text short
+## <int> <int> <int> <int> <int> <int> <chr> <lgl> <chr> <chr>
+## 1 1 1 1 47 49 0 expr FALSE
+## # ... with 9 more variables: token_before <chr>, token_after <chr>,
+## # internal <lgl>, child <list>, newlines <int>, lag_newlines <dbl>,
+## # spaces <int>, multi_line <lgl>, indent <dbl>
+
We can see how indention works with a more complicated example
+
indented <- c(
+ "call(",
+ " 1,",
+ " call2(",
+ " 2, 3,",
+ " call3(1, 2, 22),",
+ " 5",
+ " ),",
+ " 144",
+ ")"
+)
+
+not_indented <- trimws(indented)
+back_and_forth <- not_indented %>%
+ compute_parse_data_nested() %>%
+ pre_visit(c(create_filler,
+ purrr::partial(indent_round, indent_by = 2))) %>%
+ serialize_parse_data_nested()
+
+identical(indented, back_and_forth)
+
## [1] TRUE
+