



Building the next generation of efficient AI architectures.
We develop novel transformer architectures focused on determinism, efficiency, and real-time inference.
The key innovation: μ (mu) flows from layer
# Mu-Guided Attention: mu biases Q, K, V projections
q = q_proj(x) + mu_to_q(mu_prev)
k = k_proj(x) + mu_to_k(mu_prev)
v = v_proj(x) + mu_to_v(mu_prev)
# Mu-Guidance after MLP (captures which expert processed each token)
mu_current = clamp(mu_param + mu_proj(h), -2, 2)Why Mu?
- Inter-layer coordination: Previous layer's expert context informs next layer's attention
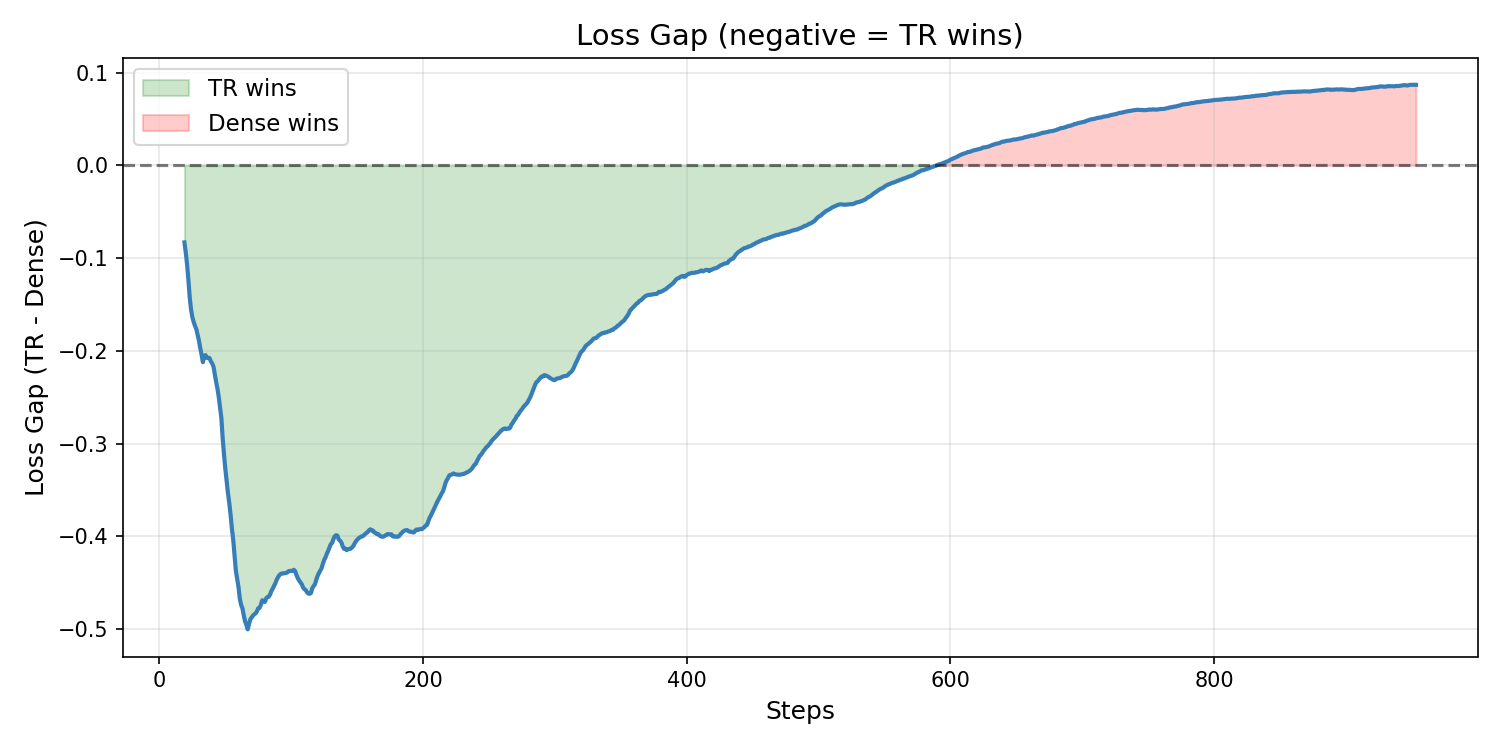
- Faster convergence: -0.112 avg loss vs dense baseline
- Essential component: Without Mu, Token-Routed is worse than dense
Zipf-balanced routing with sort-and-split dispatch:
# Zipf bin-packing: each expert gets equal frequency mass
expert_id = token_to_expert[token_id] # deterministic, zero overhead
# Sort-and-split dispatch: fixed chunks, bmm, fullgraph safe
sort_idx = expert_ids.argsort(stable=True)
# each expert processes exactly N/E tokens via bmm| Aspect | Mixtral (learned) | Token-Routed (ours) |
|---|---|---|
| Router | nn.Linear + softmax | None (table lookup) |
| Load Balancing | Auxiliary loss | Perfect by design |
| Expert Collapse | Possible | Impossible |
| CUDA Graph Safe | Special handling | Fully compatible |
| Dispatch | Gather/scatter | Sort-and-split (bmm) |
A dense SwiGLU MLP that all tokens pass through, capturing common patterns (function words, syntax). Output = shared(x) + routed(x).
Each expert specializes on its token subset while the shared expert handles universal patterns.
- KQV Order: Industry standard (Llama, Qwen, GPT) for optimal KV-cache
- GQA: Grouped Query Attention (8 KV heads)
- QK Norm: Attention stability at scale
- RoPE: Rotary positional embeddings
- Flash Attention: SDPA via PyTorch 2.0+
Input → [Embed] → mu_init (learnable)
│ │
▼ ▼
[RMSNorm] → [Mu-Guided GQA] → Residual → [RMSNorm] → [Token-Routed MLP + Shared Expert]
│ ▲ │
│ mu_prev Residual
│ │
│ [Mu-Guidance]
│ │
▼ mu_current → next layer
Output ← [Final RMSNorm] ← [LM Head (tied)]
× 18 decoder layers | 187M params | 4 experts | GQA 12h/4kv
Ablation study on 500M tokens FineWeb-Edu (iso-param ~187M):
| Configuration | Avg Loss (700 steps) |
|---|---|
| Token-Routed + Mu + Zipf | 5.026 |
| Mixtral-style (learned router) | 5.110 |
| Token-Routed without Mu | 5.127 |
| Dense SwiGLU baseline | 5.205 |
Inference: 204 tokens/s on vLLM (RTX 5060 Ti, 16GB).
| Repository | Description |
|---|---|
| complexity-framework | Training framework, model code, ablation scripts |
| vllm-cuda_graph | vLLM fork with Complexity-Deep inference support |
Simple modulo routing (token_id % 4) concentrates frequent tokens. Our Zipf-balanced bin-packing distributes tokens by corpus frequency:
- Sort vocabulary by frequency (Zipf distribution)
- Greedy assignment: each token to the least-loaded expert
- Result: each expert handles equal frequency mass, not just equal token count
pip install complexity-frameworkfrom complexity.models import ComplexityModel
from complexity.config import ModelConfig
config = ModelConfig(
hidden_size=768,
num_hidden_layers=18,
num_attention_heads=12,
num_key_value_heads=4,
intermediate_size=2048,
vocab_size=32000,
mlp_type="token_routed",
num_experts=4,
shared_expert=True,
use_mu_guidance=True,
)
model = ComplexityModel(config) # 187M params| Innovation | Description |
|---|---|
| Token-Routed MLP | Deterministic routing, no learned router |
| Sort-and-Split Dispatch | BMM dispatch, fullgraph safe, CUDA graph compatible |
| Zipf-Balanced Routing | Greedy bin-packing on corpus frequency |
| Mu-Guidance | Inter-layer communication carrying expert context |
| Shared Lexical Expert | Dense MLP for common patterns + routed experts |
| Learnable mu_init | Layer 0 also gets inter-layer guidance |
Simplicity over complexity. The best ideas are often the simplest.
- Deterministic routing instead of learned routers
- Inter-layer communication (μ) instead of complex gating networks
- Sort-and-split dispatch for GPU-friendly static shapes
- Zipf-balanced assignment for natural language statistics
Deterministic AI for a predictable future.