{kind=link}
User Agent: Mozilla, Safari, Crome, IE & Device - Detection
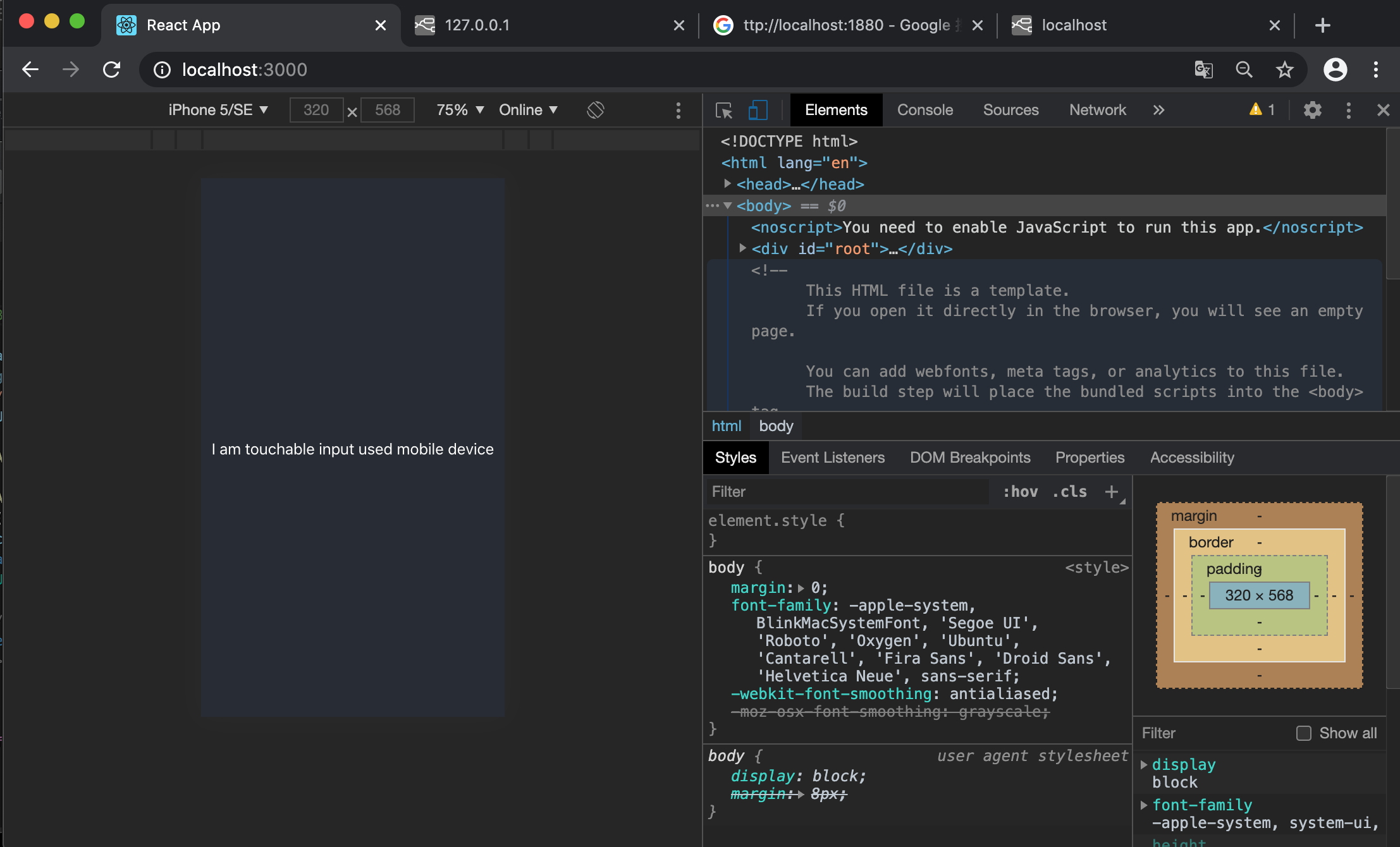
for iphone SE
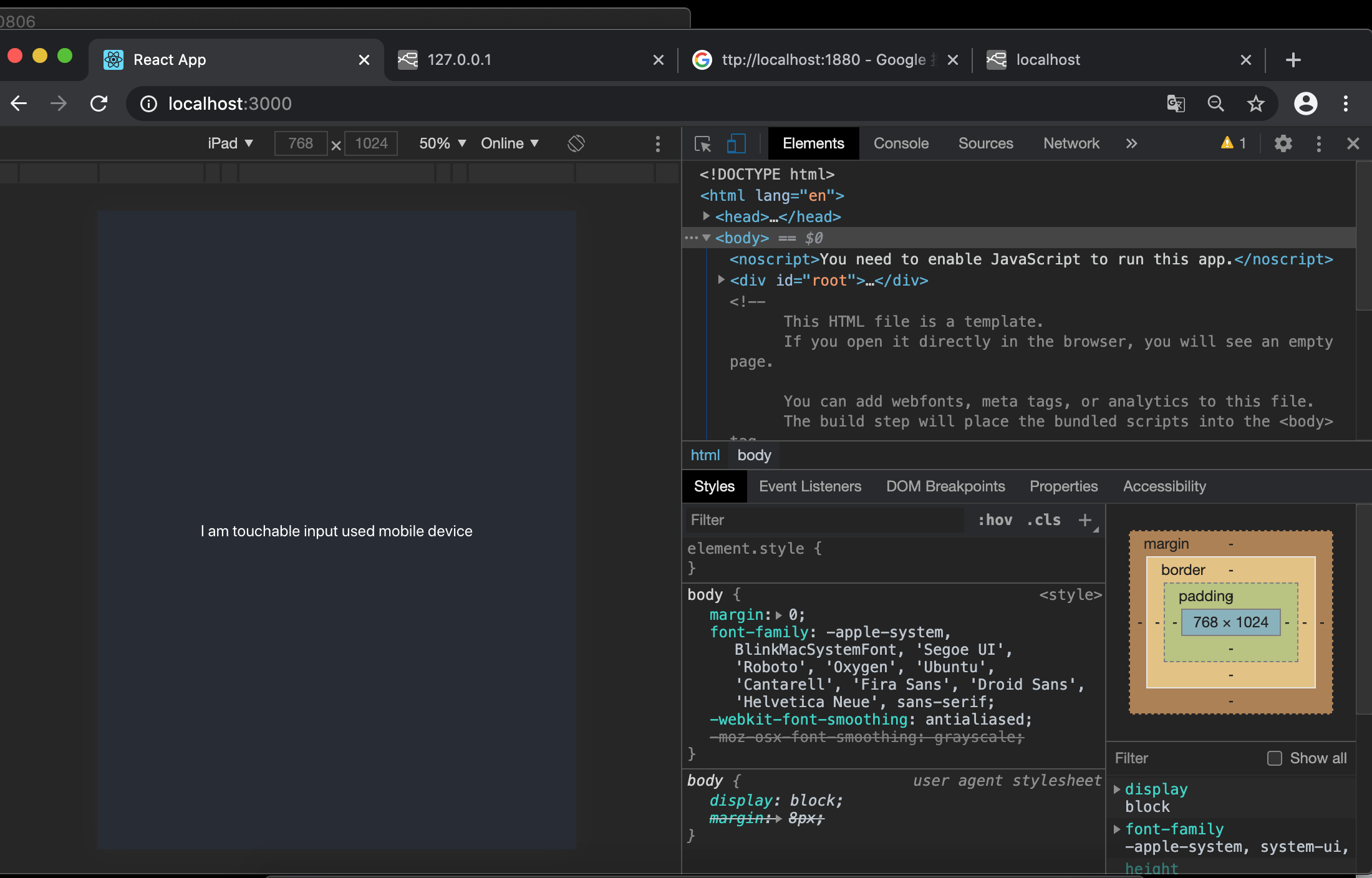
for ipad
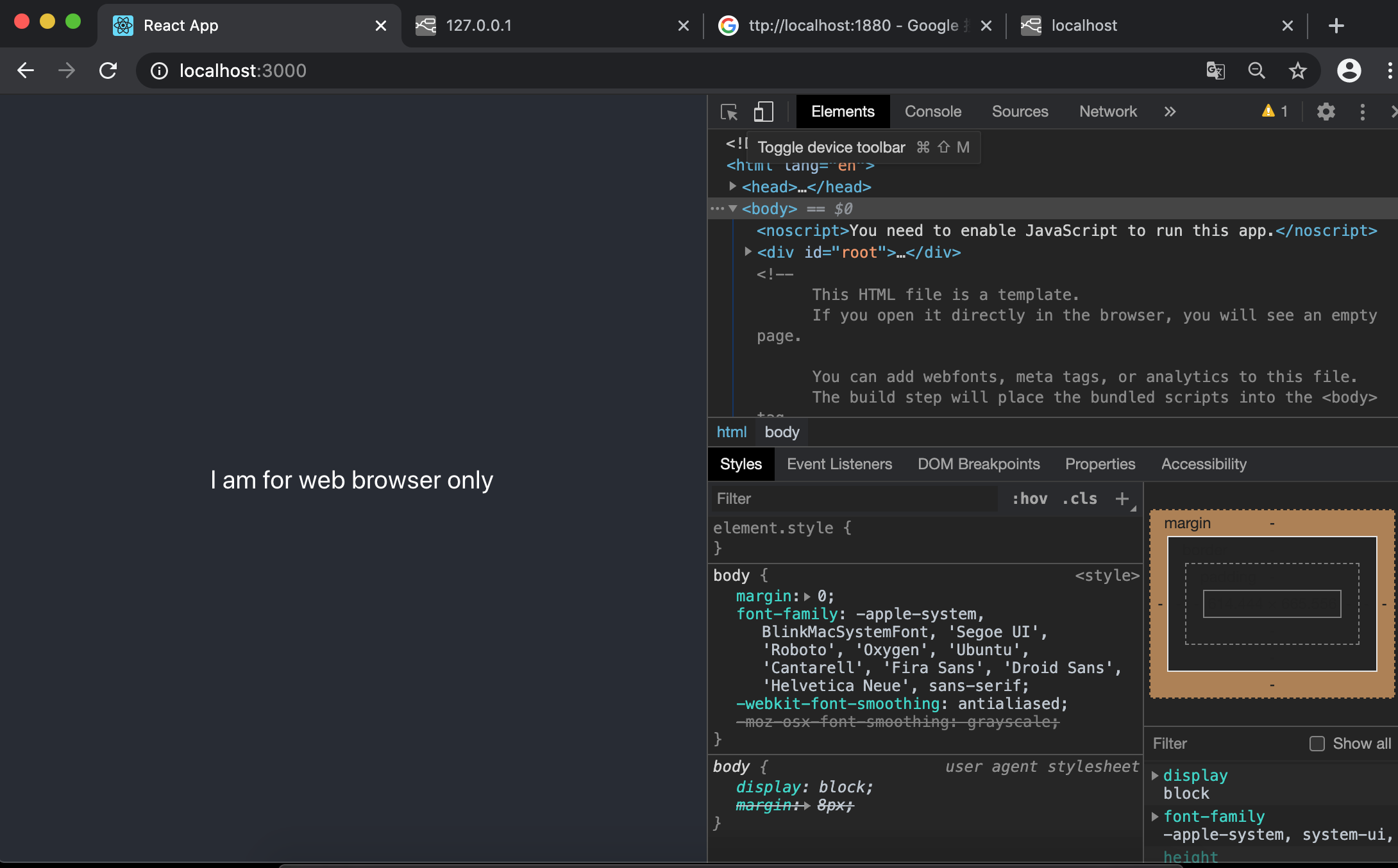
for web
ua
import React from 'react';
import logo from './logo.svg';
import './App.css';
import { UserAgent } from 'react-useragent';
function App() {
const UA = UserAgent;
return (
<div className="App">
<header className="App-header">
<UA>
{ ({ua})=> { return ua.mobile ? <p> I am touchable input used mobile device </p>: <p> I am for web browser only</p>} }
</UA>
</header>
</div>
);
}
export default App;
# https://www.robotstxt.org/robotstxt.html
User-agent: *
Disallow:
# 此檔案 與 SEO 有關。
#此檔名必須是全小寫。
#此檔案需要放置在根目錄下。
#robots.txt 檔案能夠向搜尋引擎檢索器表明,
#檢索器可/不可要求哪些網站上的網頁或檔案。
#這個檔案主要用於避免網站因要求過多而超載;
#但它不是讓特定網頁無法出現在Google 搜尋結果中的機制。
#如果您想禁止自己的網頁出現在搜尋結果中,
#應使用noindex 指令,或使用密碼保護網頁。
#上線後,要被搜索引擎收錄,才會有排名的可能。
#搜索引擎會將線上運作的網站抓到 crawl 搜索引擎清單 list 內做索引 index
#然後根據演算法做出排序
#提供使用者查詢得到資料。
#拒絕索引的情況是:
#開發者將成果部分設定為不被搜尋到抑或是暫時不被搜尋到,因而阻止了搜索引擎。
#(1)使用 meta tage 阻擋,但每個網頁都要獨立設定。
#(2)整個網站做規範限制,即本頁 robots.txt,能告知檢索中的搜索引擎他的網站哪些可以被檢索
哪些可以不用被檢索。可使用 Disallow: /*/shop/duty
#robots.txt 的參數簡介:
#(1) User-agent => 為對象,定義了下述規則對哪些搜索引擎生效。
#User-agent: * 為全部搜索引擎
#User-agent: Googlebot-image 為 Google 搜圖的爬蟲檢索。
#User-agent: bingbot 為 Bin 的爬蟲檢索。
#(2) Disallow => 需要指名路徑,指定哪些目錄或檔案類型不要被檢索。
#沒有值,就是忽略
#如值為 / 則是拒絕引擎檢索所有內容
#如值為 /aaa/ 則是拒絕引擎檢索 aaa 底下所有內容
#如值為 *.png$ 為拒絕搜索引擎檢索crawl png 為副檔名的圖檔。
#(3) Allow => 需要指名路徑,指定哪些目錄或檔案類型可能被檢索。
#(4) Sitemap => 需要使用絕對路徑,指定網站內 sitemap 檔案放置位置。
#(5) Crawl-delay: 20 # 此時間單位為秒
#測試此檔案是否有效:
#如果要驗證自己的網站有無Robots.txt,最簡單的方式是直接在網站根目錄下輸入 robotx.txt 做測試,檢驗是否存在。
#例:https://www.apple.com/robots.txt
#而若不知道目前robots.txt語法是否正確,也可以借助 Google Search Console 工具來做測試。
#也可使用 Bing Webmaster。