[toc]
学习目的:
- 学习rust语言以进一步学习操作系统
考核标准:
- 每周学习记录情况 (25%)
- 在issues上的提问和回答问题情况,Pull Request提交情况 (25%)
- step 0 要求的编程代码的完成情况 (25%)
- step 2 rcore tutorial的通过要求完成情况 (25%)
运行环境:
- wsl2+vscode
参考资料:
- 《Rust 程序设计语言》
- 《Rust By Example》




Ferris:不能编译、panic、unsafe、不会产生期望行为
2021.07.10
《Rust 程序设计语言》第一、二章
-
在wsl中安装
rustupcurl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
-
查看安装是否成功
rustc --version
-
在vscode中安装插件
rust-analyzer和Rust Syntax
Cargo 是 Rust 的构建系统和包管理器。大多数 Rustacean 们使用 Cargo 来管理他们的 Rust 项目,因为它可以为你处理很多任务,比如构建代码、下载依赖库并编译这些库。——《Rust 程序设计语言》
-
刷新当前的shell环境
source $HOME/.cargo/env
-
使用Cargo创建项目
cargo new hello
-
Cargo项目的目录结构与文件
-
Cargo.toml[package] name = "hello" version = "0.1.0" edition = "2018" [dependencies]
[package],是一个片段(section)标题,表明下面的语句用来配置一个包[dependencies],是罗列项目依赖的片段的开始,在 Rust 中,代码包被称为 crates
-
src- 用于存放源文件
- 项目根目录只存放 README、license 信息、配置文件和其他跟代码无关的文件
-
-
Cargo的基本指令
cargo build:为了开发,需要经常快速重新构建项目cargo runcargo check:编写代码时持续的进行检查cargo release:为用户构建最终程序,它们不会经常重新构建,并且希望程序运行得越快越好,但构建时间相对cargo build而言比较长
通过编写一个猜数字的程序进一步了解rust语言编程
-
首先创建一个新的项目
cargo new guessing_game
-
修改
Cargo.toml文件引入rand依赖[dependencies] rand = "0.8.3"
[dependencies]片段告诉 Cargo 本项目依赖了哪些外部 crate 及其版本- 采用语义化版本
0.8.3来指定randcrate,0.8.3事实上是^0.8.3的简写
-
通过Cargo.lock文件确保构建可重现
-
当第一次构建项目时,Cargo 计算出所有符合要求的依赖版本并写入 Cargo.lock 文件
-
当将来构建项目时,Cargo 会发现 Cargo.lock 已存在并使用其中指定的版本,而不是再次计算所有的版本
-
这意味着项目会持续使用
0.8.3,直到显式升级-
可以使用
create update升级,但不能升级到0.9.x的版本 -
想要升级到
0.9.x的版本必须要更新Cargo.coml文件[dependencies] rand = "0.9.0"
-
-
use rand::Rng;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..101);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {}", guess);
match guess.cmp(&secret_number) {
std::cmp::Ordering::Less => println!("Too small!"),
std::cmp::Ordering::Greater => println!("Too big!"),
std::cmp::Ordering::Equal => {
println!("You win!");
break;
}
}
}
}-
use rand::Rng;use std::io;- 使用
use语句显式地将需要使用的类型引入作用域
- 使用
-
fn main(){}程序入口 -
let secret_number = rand::thread_rng().gen_range(1..101);- 定义了一个不可变的变量并通过随机数发生器赋值
-
let mut guess = String::new();- 定义了一个可变的字符串变量
guess
- 定义了一个可变的字符串变量
-
读入字符串变量并处理expect
io::stdin() .read_line(&mut guess) .expect("Failed to read line");
- 注意不能将
&mut guess写为&guess read_line()返回io:Result类型的值,用于expect的处理
- 注意不能将
-
将输入的字符串转化为数字
let guess: u32 = match guess.trim().parse() { Ok(num) => num, Err(_) => continue, };
- 虽然已经定义了一个
guess变量,但Rust允许用一个新值来 隐藏guess之前的值,常用在需要转换值类型之类的场景 - 将
guess绑定到guess.trim().parse()表达式上 : u32表示指定变量类型为无符号的32位整型- 通过
match来匹配转化成功与失败时的下一步操作- 疑问:这里为什么需要写成
Ok(num)与Err(_),传入的参数有什么必要性?
- 疑问:这里为什么需要写成
- 虽然已经定义了一个
-
println!("You guessed: {}", guess);- 打印输入,采用占位符
{}
- 打印输入,采用占位符
-
通过
match来匹配不同输入下程序运行的结果match guess.cmp(&secret_number) { std::cmp::Ordering::Less => println!("Too small!"), std::cmp::Ordering::Greater => println!("Too big!"), std::cmp::Ordering::Equal => { println!("You win!"); break; } }
今天安装了 rust ,配置了相对应的环境,了解使用了 cargo 来管理构建项目,并通过编写一个简易的 rust 程序大致了解了 rust 的基本语法与使用习惯,为进一步的学习做好准备。
2021.07.11
《Rust 程序设计语言》第一、二章
- 变量默认是不可改变的(immutable)
- 这是推动以充分利用 Rust 提供的安全性和简单并发性来编写代码的众多方式之一
- 可以在变量名之前加
mut来使其可变。 - 常量
const- 命名规范是使用下划线分隔的大写字母单词
- 硬编码值
-
定义一个与之前变量同名的新变量,而新变量会 隐藏 之前的变量
-
隐藏与将变量标记为
mut的区别-
隐藏在重新赋值时需要使用
let关键字 -
再次使用
let时,实际上创建了一个新变量,我们可以改变值的类型,但复用这个名字let spaces = " "; let spaces = spaces.len();
-
mut赋值时不能改变变量的类型,以下代码编译时错误let mut spaces = " "; spaces = spaces.len();
-
标量(scalar)和复合(compound)
- Rust 是 静态类型(statically typed)语言,在编译时就必须知道所有变量的类型
- 根据值及其使用方式,编译器通常可以推断出我们想要用的类型
- 当多种类型均有可能时,必须增加类型注解
标量(scalar)类型代表一个单独的值。Rust 有四种基本的标量类型:整型、浮点型、布尔类型和字符类型
整形
| 长度 | 有符号 | 无符号 |
|---|---|---|
| 8-bit | i8 |
u8 |
| 16-bit | i16 |
u16 |
| 32-bit | i32 |
u32 |
| 64-bit | i64 |
u64 |
| 128-bit | i128 |
u128 |
| arch | isize |
usize |
-
isize和usize类型依赖运行程序的计算机架构 -
除 byte 以外的所有数字字面值允许使用类型后缀,例如
57u8 -
允许使用
_做为分隔符以方便读数,例如1_000 -
Rust 中整型字面值
数字字面值 例子 Decimal (十进制) 98_222Hex (十六进制) 0xffOctal (八进制) 0o77Binary (二进制) 0b1111_0000Byte (单字节字符)(仅限于 u8)b'A' -
整形溢出

==如何复现?==
浮点型
- Rust 的浮点数类型是
f32和f64 - 浮点数采用 IEEE-754 标准表示
数值运算
- 可以在
let语句中使用
布尔型
字符类型
- Rust 的
char类型是语言中最原生的字母类型 char由单引号指定,不同于字符串使用双引号- Rust 的
char类型的大小为四个字节(four bytes),并代表了一个 Unicode 标量值(Unicode Scalar Value)
复合类型(Compound types)可以将多个值组合成一个类型。Rust 有两个原生的复合类型:元组(tuple)和数组(array)
元组类型
-
将多个其他类型的值组合进一个复合类型的主要方式,长度固定
-
使用包含在圆括号中的逗号分隔的值列表来创建一个元组
let tup: (i32, f64, u8) = (500, 6.4, 1); -
为了从元组中获取单个值,可以使用模式匹配(pattern matching)来解构(destructure)元组值
let (x, y, z) = tup; -
可以使用点号(
.)后跟值的索引来直接访问let five_hundred = x.0; let six_point_four = x.1; let one = x.2;
数组类型
-
数组中的每个元素的类型必须相同,固定长度
-
数组的初始化
-
数组中的值位于中括号内的逗号分隔的列表中
let a = [1, 2, 3, 4, 5]; -
在方括号中包含每个元素的类型,后跟分号,再后跟数组元素的数量
let a: [i32; 5] = [1, 2, 3, 4, 5]; -
如果要为每个元素创建包含相同值的数组,可以指定初始值,后跟分号,然后在方括号中指定数组的长度
let a = [3; 5];
-
-
在栈(stack)而不是在堆(heap)上为数据分配空间
-
访问数组元素越界
编译并没有产生任何错误,不过程序会出现一个 运行时(runtime)错误panic
-
fn关键字,它用来声明新函数 -
Rust 代码中的函数和变量名使用 snake case 规范风格
- 所有字母都是小写并使用下划线分隔单词
-
参数(parameters)是特殊变量,是函数签名的一部分
- 在函数签名中,必须 声明每个参数的类型
-
函数体由一系列的语句和一个可选的结尾表达式构成
-
语句(Statements)是执行一些操作但不返回值的指令
let y = 6语句并不返回值,所以在let x = (let y = 6);中没有可以绑定到x上的值
-
表达式(Expressions)计算并产生一个值,结尾没有分号
-
函数调用是一个表达式
-
宏调用是一个表达式
-
{},也是一个表达式,代码块的值是其最后一个表达式的值fn main() { let x = 5; let y = { let x = 3; x + 1 }; println!("The value of y is: {}", y); }
-
-
-
函数的返回值
- 不对返回值命名,但要在箭头(
->)后声明它的类型 - 使用
return关键字和指定值,可从函数中提前返回 - 但大部分函数隐式的返回最后的表达式
- 使用空元组
()表示不返回值。
- 不对返回值命名,但要在箭头(
Rust 代码中最常见的用来控制执行流的结构是 if 表达式和循环
if 表达式
-
if表达式中与条件关联的代码块有时被叫做 arms -
代码中的条件 必须 是
bool值 -
if是一个表达式,我们可以在let语句的右侧使用它 -
if的每个分支的可能的返回值都必须是相同类型- Rust 需要在编译时就确切的知道
number变量的类型,这样它就可以在编译时验证在每处使用的number变量的类型是有效的
- Rust 需要在编译时就确切的知道
-
使用过多的
else if表达式会使代码显得杂乱无章,所以如果有多于一个else if表达式,最好重构代码
使用 loop 重复执行代码
- 使用
break关键字来停止循环- 将返回值加入用来停止循环的
break表达式,它会被停止的循环返回
- 将返回值加入用来停止循环的
while 条件循环
使用 for 遍历集合
-
对数组中的元素进行计数索引
fn main() { let a = [10, 20, 30, 40, 50]; let mut index = 0; while index < 5 { println!("the value is: {}", a[index]); index = index + 1; } }
- 很容易出错
-
使用
for循环来对一个集合的每个元素执行一些代码fn main() { let a = [10, 20, 30, 40, 50]; for element in a.iter() { println!("the value is: {}", element); } }
- 增强了代码安全性
- 消除了可能由于超出数组的结尾或遍历长度不够而缺少一些元素而导致的 bug
-
使用
for循环来倒计时fn main() { for number in (1..4).rev() { println!("{}!", number); } println!("LIFTOFF!!!"); }
rev,用来反转 range
所有权(系统)是 Rust 最为与众不同的特性,它让 Rust 无需垃圾回收(garbage collector)即可保障内存安全。Rust 则选择通过所有权系统管理内存,编译器在编译时会根据一系列的规则进行检查。在运行时,所有权系统的任何功能都不会减慢程序。
-
所有权的存在就是为了管理堆数据
- 跟踪哪部分代码正在使用堆上的哪些数据
- 最大限度的减少堆上的重复数据的数量
- 以及清理堆上不再使用的数据确保不会耗尽空间
-
所有权规则
- Rust 中的每一个值都有一个被称为其 所有者(owner)的变量
- 值在任一时刻有且只有一个所有者
- 当所有者(变量)离开作用域,这个值将被丢弃
-
变量的作用域
- 当
s进入作用域 时,它就是有效的 - 这一直持续到它 离开作用域 为止
- 当
-
let s = String::from("hello");-
常用rust字符串类型为&str和String,前者是字符串的引用,后者是基于堆创建的,可增长的字符串
-
使用
from函数基于字符串字面值来创建String -
此处两个冒号(
::)是运算符,允许将特定的from函数置于String类型的命名空间(namespace)下 -
String可变而字面值不可变,其原因在于两个类型对于内存的处理不同- 字面值硬编码,而 String 类型存储在堆上
-
-
当变量离开作用域,Rust 为调用
drop函数释放内存- 资源获取即初始化(Resource Acquisition Is Initialization (RAII))
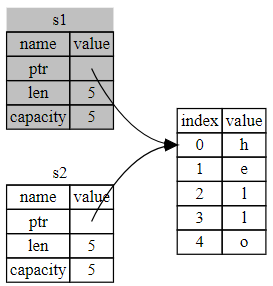
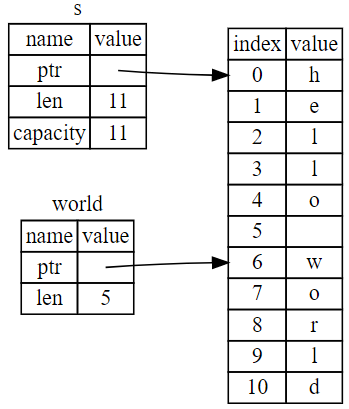
let s1 = String::from("hello");
let s2 = s1;-
将值
"hello"绑定给s1的String在内存中的表现形式
String由三部分组成,如图左侧所示- 指向存放字符串内容内存的指针、长度、容量
- 注意长度与容量的区别
- 右侧则是堆上存放内容的内存部分
-
将
s1赋值给s2,String的数据被复制了
- 从栈上拷贝了它的指针、长度和容量
- 并没有复制指针指向的堆上数据
-
s1被 移动 到了s2中
- 为了避免 二次释放(double free)的错误,与其尝试拷贝被分配的内存,Rust 则认为
s1不再有效 - Rust 不需要在
s1离开作用域后清理任何东西 - 只有
s2是有效的,当其离开作用域,它就释放自己的内存
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);- 使用
clone函数深度复制String中堆上的数据

- 只在栈上的数据无需使用
clone函数即可 拷贝 Copytrait- 如果一个类型拥有
Copytrait,一个旧的变量在将其赋值给其他变量后仍然可用 - Rust 不允许自身或其任何部分实现了
Droptrait 的类型使用Copytrait
- 如果一个类型拥有
- copy 类型
- 所有整数类型,比如
u32 - 布尔类型,
bool,它的值是true和false - 所有浮点数类型,比如
f64 - 字符类型,
char - 元组,当且仅当其包含的类型也都是
Copy的时候。比如,(i32, i32)是Copy的,但(i32, String)就不是
- 所有整数类型,比如
-
向函数传递值可能会移动或者复制
fn main() { let s = String::from("hello"); // s 进入作用域 takes_ownership(s); // s 的值移动到函数里 ... // ... 所以到这里不再有效 let x = 5; // x 进入作用域 makes_copy(x); // x 应该移动函数里, // 但 i32 是 Copy 的,所以在后面可继续使用 x } // 这里, x 先移出了作用域,然后是 s。但因为 s 的值已被移走, // 所以不会有特殊操作 fn takes_ownership(some_string: String) { // some_string 进入作用域 println!("{}", some_string); } // 这里,some_string 移出作用域并调用 `drop` 方法。占用的内存被释放 fn makes_copy(some_integer: i32) { // some_integer 进入作用域 println!("{}", some_integer); } // 这里,some_integer 移出作用域。不会有特殊操作
-
返回值也可以转移所有权
文件名: src/main.rs fn main() { let s1 = gives_ownership(); // gives_ownership 将返回值 // 移给 s1 let s2 = String::from("hello"); // s2 进入作用域 let s3 = takes_and_gives_back(s2); // s2 被移动到 // takes_and_gives_back 中, // 它也将返回值移给 s3 } // 这里, s3 移出作用域并被丢弃。s2 也移出作用域,但已被移走, // 所以什么也不会发生。s1 移出作用域并被丢弃 fn gives_ownership() -> String { // gives_ownership 将返回值移动给 // 调用它的函数 let some_string = String::from("hello"); // some_string 进入作用域. some_string // 返回 some_string 并移出给调用的函数 } // takes_and_gives_back 将传入字符串并返回该值 fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域 a_string // 返回 a_string 并移出给调用的函数 }
-
变量的所有权总是遵循相同的模式
- 将值赋给另一个变量时移动它
- 当持有堆中数据值的变量离开作用域时,其值将通过
drop被清理掉,除非数据被移动为另一个变量所有
以一个对象的引用作为参数而不是获取值的所有权
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
} // 这里,s 离开了作用域。但因为它并不拥有引用值的所有权,
// 所以什么也不会发生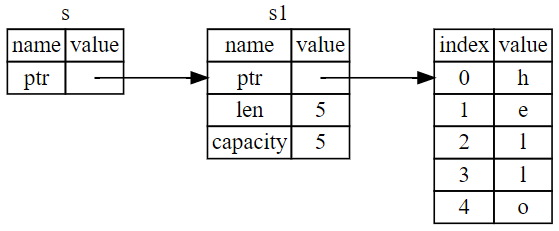
- & 符号就是 引用,它们允许使用值但不获取其所有权
- 与使用
&引用相反的操作是 解引用(dereferencing),它使用解引用运算符,*
- 与使用
- 将获取引用作为函数参数称为 借用(borrowing)
- (默认)不允许修改引用的值
可变引用
-
将
s改为mut。然后必须创建一个可变引用&mut s和接受一个可变引用some_string: &mut Stringfn main() { let mut s = String::from("hello"); change(&mut s); } fn change(some_string: &mut String) { some_string.push_str(", world"); }
-
在特定作用域中的特定数据只能有一个可变引用,以下代码无效
let mut s = String::from("hello"); let r1 = &mut s; let r2 = &mut s; println!("{}, {}", r1, r2);
- 可以避免 数据竞争(data race)
- 两个或更多指针同时访问同一数据
- 至少有一个指针被用来写入数据
- 没有同步数据访问的机制
- 可以避免 数据竞争(data race)
-
多个不可变引用是可以的,但不能在拥有不可变引用的 同时 拥有可变引用
let mut s = String::from("hello"); let r1 = &s; // 没问题 let r2 = &s; // 没问题 let r3 = &mut s; // 大问题 println!("{}, {}, and {}", r1, r2, r3);
-
注意一个引用的作用域从声明的地方开始一直持续到 最后一次使用 为止。例如,因为最后一次使用不可变引用在声明可变引用之前,所以如下代码是可以编译的:
let mut s = String::from("hello"); let r1 = &s; // 没问题 let r2 = &s; // 没问题 println!("{} and {}", r1, r2); // 此位置之后 r1 和 r2 不再使用 let r3 = &mut s; // 没问题 println!("{}", r3);
悬垂引用
在具有指针的语言中,很容易通过释放内存时保留指向它的指针而错误地生成一个 悬垂指针(dangling pointer)
Rust 编译器确保数据不会在其引用之前离开作用域
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s // 返回字符串 s 的引用
} // 这里 s 离开作用域并被丢弃。其内存被释放。
// 危险!引用的规则
- 在任意给定时间,要么 只能有一个可变引用,要么 只能有多个不可变引用。
- 引用必须总是有效的。
-
没有所有权
-
引用集合中一段连续的元素序列,而不用引用整个集合
-
找到字符串中第一个单词结尾索引
fn first_word(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return i; } } s.len() }
as_bytes方法将String转化为字节数组- 但返回值与
String相分离,无法保证将来它仍然有效
-
使用
slice确保指向String的引用持续有效fn first_word(s: &String) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] }
iter方法返回集合中的每一个元素,而enumerate包装了iter的结果,将这些元素作为元组的一部分来返回
-
使用一个由中括号中的
[starting_index..ending_index]指定的 range 创建一个 slice,左闭右开-
如果想要从第一个索引(0)开始,可以不写两个点号之前的值
let s = String::from("hello"); let slice = &s[0..2]; let slice = &s[0..=1]; let slice = &s[..2];
-
同时舍弃这两个值来获取整个字符串的 slice
let s = String::from("hello"); let len = s.len(); let slice = &s[0..len]; let slice = &s[..];
-
-
slice 字符串基于utf-8,需要注意中文为3字节,而char为4字节
-
clear需要清空String,需要获取一个可变引用,而当拥有某值的不可变引用时,就不能再获取一个可变引用,因此一下代码会报错fn main() { let mut s = String::from("hello world"); let word = first_word(&s); s.clear(); // 错误! println!("the first word is: {}", word); } fn first_word(s: &String) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] }
-
字符串字面值就是
slicelet s = "Hello, world!";- 这里
s的类型是&str:它是一个指向二进制程序特定位置的 slice - 这也就是为什么字符串字面值是不可变的;
&str是一个不可变引用 - 改进
first_word的签名:fn first_word(s: &str) -> &str {
-
其他类型的 slice
大体上了解了 rust 的基本语法规则,其中所有权的概念比较新颖不是很好理解。目前大概将所有权理解成一块饼干,给了别人自己就没有了。
尝试了简单的rust编程,发现难度比想象的要大得多,陌生的语法以及所有权规则让我很难流畅的写出可以正常通过编译的代码。接下来的几天需要增加一些编程练习来巩固知识帮助理解。
在大体上浏览了一些之后的章节后,发现学习曲线非常陡峭。做好心理准备,继续加油。