中文词向量训练的问题 #8
Description
你好,我用于测试的中文数据格式如下:
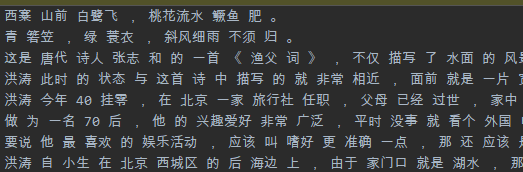
每行是一个已经分词的句子
word表的大小是9w,char表的大小是3600
ELMo的batch_size是128(原配置是1024,但是我机器不行,改成128了),其他不变,跑出来的结果是这样:

损失没啥问题,但是精度最高只有1点几。。。想问下这个是哪里的问题?
我按照你的代码写的是这样的:
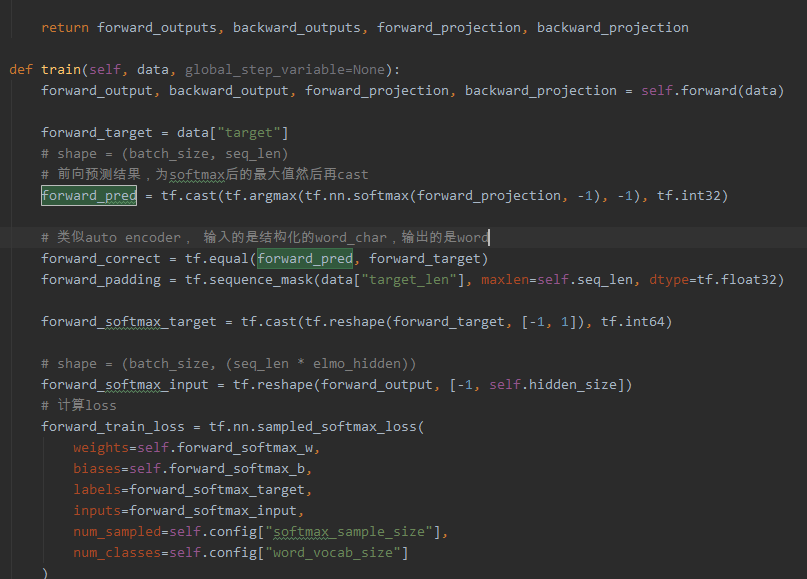
另外,我现在训练好模型后,怎么获取到中文词向量呢?
万分感谢!
你好,我用于测试的中文数据格式如下:
每行是一个已经分词的句子
word表的大小是9w,char表的大小是3600
ELMo的batch_size是128(原配置是1024,但是我机器不行,改成128了),其他不变,跑出来的结果是这样:
损失没啥问题,但是精度最高只有1点几。。。想问下这个是哪里的问题?
我按照你的代码写的是这样的:
另外,我现在训练好模型后,怎么获取到中文词向量呢?
万分感谢!