A single-threaded and multi-threaded version of a C++ implementation of the Smith-Waterman algorithm was tested and compared. Results indicate limited speedup on modern hardware using threads using a single sample file.
The single threaded version goes row-by-row through the matrix and calculates the score.
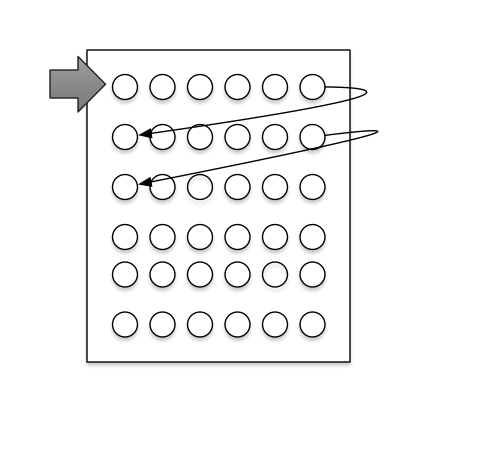
The multi-threaded version dispatches threads on each row to process until the last row. As soon as a thread is finished processing, it moves on to the next row. If one thread gets ahead of the other it waits until the top thread fulfills the bottom threads dependency.
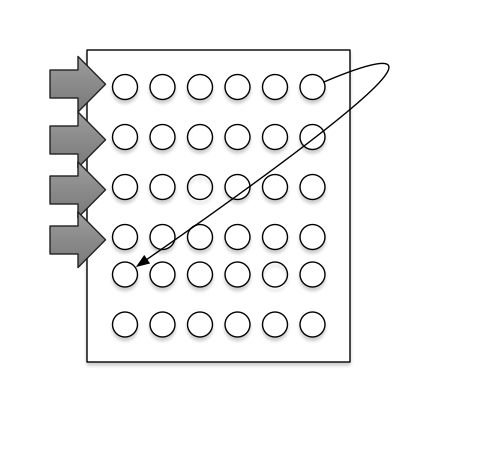
C++14 standard library with Clang++/LLVM 3.7.0 was chosen due to availability of Mac OS. C++11 threads were used in the threaded version due to the more simple implementation compared to pthreads. The program accepted arguments for number of threads. If the argument for threads is equal to one, none of the C++ threading API was called. If the number of threads was 2 or more, the known sequence (smaller) was split up between the available threads, going in order from top to bottom. Level 2 optimizations were enabled for compilation due to anecdotal evidence resulting in reduced processing time.
 A Macbook Pro, Early 2015 with a 2.7GHz Core i5 processor with 8GB of DDR3 RAM was compared to a Mac Mini from Mid-2011 with a 2.3GHz processor and 8GB of DDR3. Each test of threads was run for 4 iterations to ensure consistent test results. The program was run with threads between 1-10, 12 and 16 threads and compared. The clock API of C++ was used to record only the processing time of both the threaded and non-threaded code execution. The time for initialization and file reading was ignored in all cases.
A Macbook Pro, Early 2015 with a 2.7GHz Core i5 processor with 8GB of DDR3 RAM was compared to a Mac Mini from Mid-2011 with a 2.3GHz processor and 8GB of DDR3. Each test of threads was run for 4 iterations to ensure consistent test results. The program was run with threads between 1-10, 12 and 16 threads and compared. The clock API of C++ was used to record only the processing time of both the threaded and non-threaded code execution. The time for initialization and file reading was ignored in all cases.
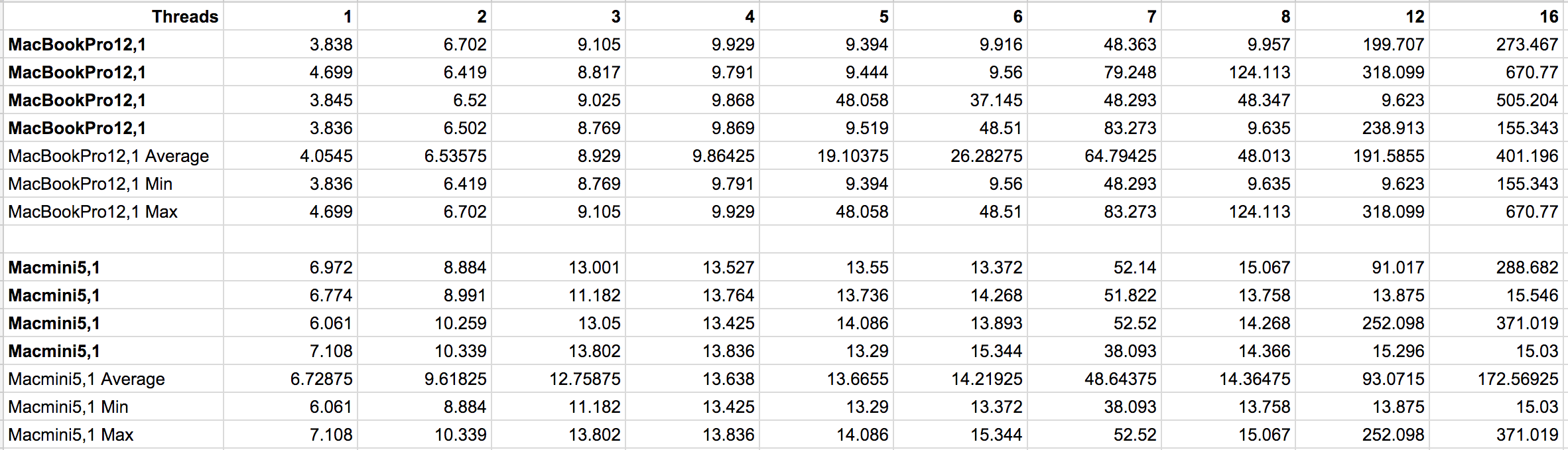
Here is the raw data of the test runs.
Of the parallelized test runs, two threads performed the best on all hardware. These runs graphed:
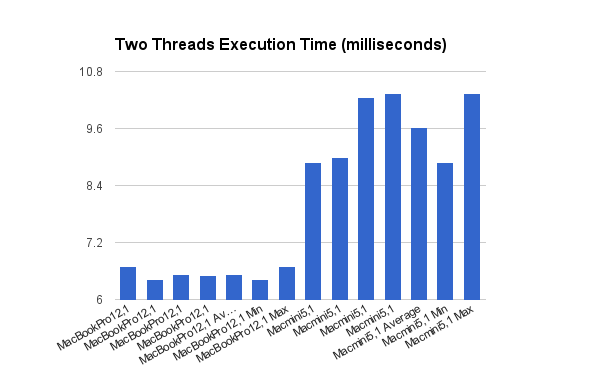
Graphing the run times of the best threaded/parallel run next to the symmetrical.
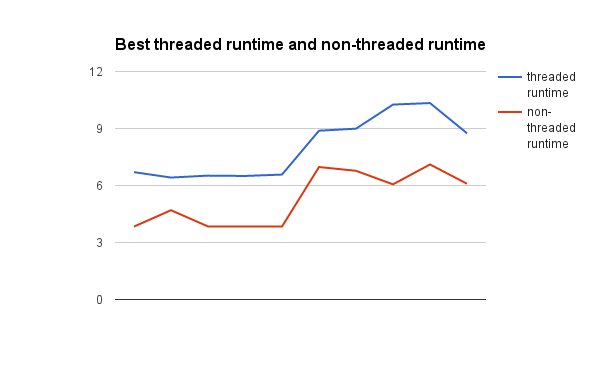
In every case, the symmetrical / single-threaded version of the application ran faster than the parallelized version. This suggests that the overhead of the threads and splitting up the work takes more time than just running through the program one time. Another suggestion is that under the hood, the compiler is doing some optimizations that reduces processing time in the single threaded case.
Dynamic programming can be valuable for speeding up execution time for even complex problems with dependencies. In this example case, it didn't result in a speed-up; but was very close to single-threaded execution. With an increase in data, this speedup difference could become profound.