Bucketize autoscaling metrics by timeframe not by pod name. #2977
Description
Current behavior
All metrics obtained by the autoscaler are bucketized by the pod that sent them. For each pod, a weight is calculated, stating how long it was active for the current autoscaling window. If a pod shuts down in the middle of the current window, its reported numbers will only be taken into account for 50%. The average concurrency for each pod is calculated over the entire scaling window (horizontal bars in the image). The average concurrency per pod is then obtained by dividing this value by the observed pods number. Observed pods is the weighted amount of pods that sent metrics for the current autoscaling window.
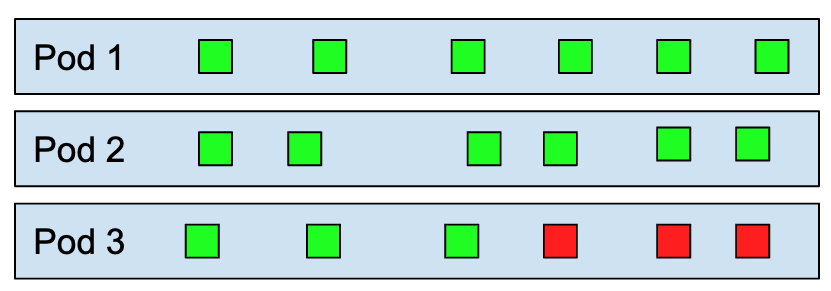
When the activator comes into play, things get more complicated. As we're always looking at the average per pod over time, we do the same for the activator. There is a bit of logic that decides though whether we act on the activator's metrics or on the queue-proxy based metrics. This is error prone and not optimal in edge-cases and in general neglects the activator metrics once we do the switch to queue-metrics and vice-versa. With the ongoing work of throttling requests in the activator, this will become problematic.
Proposed behavior
Instead of calculating the average concurrency per pod over time (bucketizing by pod name), I propose we bucketize by time. Essentially, that means we calculate the average concurrency of the whole system per timeframe. That means, for every timeframe, we calculate the average concurrency per pod in that timeframe (vertical bars). At the end, we take an average over all of these values to reach the average concurrency per pod over the whole autoscaling window.
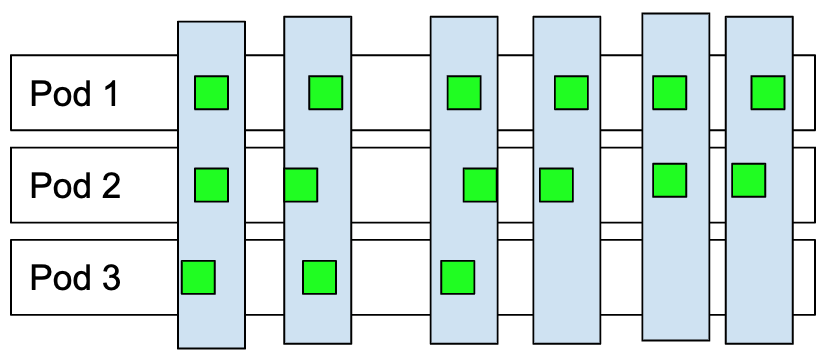
That has the advantage of not needing the concept of "lameducking" or calculating weighted pods at all. In this model, the activator metrics are also easier to integrate as they just contribute to the overall concurrency at a given timeframe. The activator pods are only taken out of the equation when calculating the average concurrency per pod for that timeframe, as they don't contribute to work actually being done by the system. Overall that gives us the advantage of not having to decide whether we decide based on activator metrics vs. queue-proxy metrics but really merges both metric streams into one more straightforward model.