Normalize Chinese by Z, Simplified, Semantic, Old, and Wrong variants #162
Conversation
|
Hello @choznerol, Nice PR! 1. Also normalizing old and wrong! variants
I'm trusting you on this. 😄 2. Confirm direction of conversion
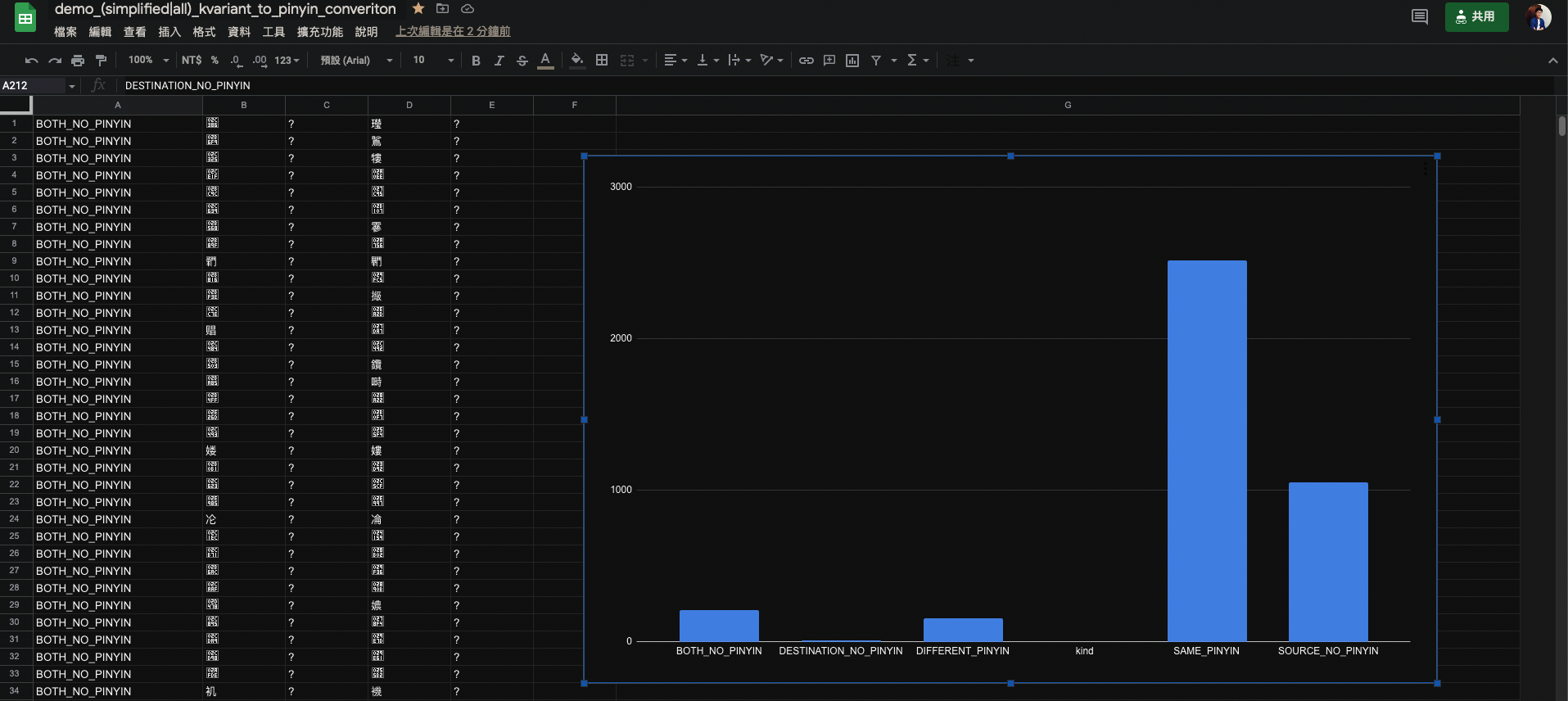
I tried to convert every codepoint of the dictionary into Pinyin to see in which proportions we managed to have a conversion. Most of the time, the pinyin normalizer manages to convert the output variants, but, sometimes, the output has no conversion where the input has. // Normalize Z, Simplified, Semantic, Old, and Wrong variants
let kvariant = match KVARIANTS.get(&c) {
Some(kvariant) => kvariant.destination_ideograph,
None => c,
};
// Normalize to Pinyin
// If we don't manage to convert the kvariant, we try to convert the original character.
// If none of them are converted, we return the kvariant.
match kvariant.to_pinyin().or_else(|| c.to_pinyin()) {
Some(converted) => {
let with_tone = converted.with_tone();
Some(with_tone.to_string().into())
}
None => Some(kvariant.into()),
}However, if you think that maximizing the Pinyin conversion is a bad idea, let me know. 3. Alternatives to copying and embedding the dictionary
Yes! I'd prefer to have a dictionary keeping only the useful data in order to reduce the crate size. |
src/normalizer/chinese.rs
Outdated
| @@ -4,6 +4,9 @@ use super::CharNormalizer; | |||
| use crate::detection::{Language, Script}; | |||
| use crate::normalizer::CharOrStr; | |||
| use crate::Token; | |||
| use kvariants::KVARIANTS; | |||
|
|
|||
| mod kvariants; | |||
|
|
|||
| /// Normalize Chinese characters by converting them into Pinyin characters. | |||
There was a problem hiding this comment.
We should change this documentation
I also tried the
Here is my interpretation of demo_simplified_kvariant_to_pinyin_converiton:
This interpretation also applys to demo_all_kvariant_to_pinyin_converiton |
Co-authored-by: ManyTheFish <[email protected]>
Ah, I see, that makes sense! I am interested in addressing this. Will do in another follow-up PR. |
…-simplified-and-semantic-variants
|
Build succeeded: |
| // 㓻 (U+34FB) sem 剛 (U+525B) | ||
| // ... | ||
| // | ||
| let file = fs::File::open("dictionaries/txt/chinese/kVariants.tsv").unwrap(); |
There was a problem hiding this comment.
Hi @ManyTheFish I just realized (during dictionary compression survey) that I probably should have use include_bytes! instead of File::open here. Not sure if this will break when packaged and released. I'm working on a follow-up PR to fix it.
There was a problem hiding this comment.
Hello @choznerol, nice! Thank you!
165: Fix incorrect File::read for kVariants.tsv r=ManyTheFish a=choznerol # Pull Request ## Related issue Fixes https://github.com/meilisearch/charabia/pull/162/files#r1029294766 ## What does this PR do? In #162, I use `File::open` to import `kVariants.tsv`, which I'm not sure if it will work after packaged to create. In this PR I switch to use `include_str!` instead. ## PR checklist Please check if your PR fulfills the following requirements: - [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)? - [x] Have you read the contributing guidelines? - [x] Have you made sure that the title is accurate and descriptive of the changes? Thank you so much for contributing to Meilisearch! Co-authored-by: Lawrence Chou <[email protected]>
Pull Request
Related issue
Fixes #144
What does this PR do?
As titled, use
kVariants.txtas a dictionary to enhance Chinese normalization.TBD
1. Also normalizing
oldandwrong!variantsThere are also
oldandwrong!variants inkVariants.txt. I didn't see a reason not also to handle them, so they are also convert.2. Confirm direction of conversion
For
=old,sem,wrong!variants, I think it's obvious we want to convert from Source Ideograph to Destination Ideograph. However, forsimpI personally think the same but am not 100% sure if there would be other considerations. The reason I think traditional variants should be the normalized form includes:=old,semandwrong!all represent source of truth.ToPinyincould be handled these simplified variants correctly if they are chosen as normalized form.3. Alternatives to copying and embedding the dictionary
If there is a preferred way to improve vendoring the dictionary (e.g. create a crate for this?), I'd love to look into it, but probably in a separate follow-up PR.
PR checklist
Please check if your PR fulfills the following requirements:
Thank you so much for contributing to Meilisearch!