Update graph construction design doc #3862
Conversation
| In particular, the first line `x = layer.data("images")` creates variable x and a Feed operator that copies a column from the minibatch to x. `y = layer.fc(x)` creates not only the FC operator and output variable y, but also two parameters, W and b. | ||
| In particular, the first line `x = layer.data("images")` creates variable x and a Feed operator that copies a column from the minibatch to x. `y = layer.fc(x)` creates not only the FC operator and output variable y, but also two parameters, W and b, and the initialization operators. | ||
|
|
||
| Initialization operators are kind of "run-once" operators -- the `Run` method increments a class data member counter so to run at most once. By doing so, a parameter wouldn't be initialized repeatedly, say, in every minibatch. |
There was a problem hiding this comment.
run-once maybe not a very good choice. Because sometimes the user may want to reinitialize the params. Maybe we should think out some better way to do it.
There was a problem hiding this comment.
Agreed. It would be great if we can have another solution. How about we keep the run-once operator as a viable solution right now, and update it later after we got a better idea?
| - construct the backward part | ||
| - construct the optimization part | ||
|
|
||
| ## The Construction of a Graph |
There was a problem hiding this comment.
Sorry, have some comment for the part that is not from this PR:
optimize(cost)
train(cost, reader=mnist.train())I think train should use the var returned by optimizer as argument, not cost. For example if two optimizer is connected with the cost, only specifying the cost the engine would have confusion of with optimizer to run.
There was a problem hiding this comment.
I think the training needs 1) the cost, and 2) the parameter to be optimized to minimize the cost.
The cost is specified in the invocation to train.
Parameters could be created by a layer function like layer.fc, or the user via W = paddle.Var(type=parameter, ...). Anyway, they are marked parameters and can be updated.
So both cost and parameter are known prior to training. What do you think about this approach?
There was a problem hiding this comment.
the training needs 1) the cost, and 2) the parameter to be optimized to minimize the cost.
I think it need the optimizer as well (Adam or Adagrad).
For example, it user do something like:
opt0 = pd.Adam(cost)
opt1 = pd.Adagrad(cost)
train(cost, reader=mnist.train())What optimizer will Paddle use for training? Maybe the code below is more concise:
opt0 = pd.Adam(cost)
opt1 = pd.Adagrad(cost)
train(opt1, reader=mnist.train())However, I just realized the Python code you wrote is perhaps the V2 API, which maybe only allow one optimizer to be connected with the cost.
There was a problem hiding this comment.
Yes. What I mean is that we can have two forms of Block::Eval:
-
One accepts targets of type
Variables:void Block::Eval(vector<Variable*> targets);
which is used to do forward computation. It traces only operators in
BlockDesc::opsbeforetargets.-
Forward computation: Because our Python API doesn't expose gradient variables to users,
targetshave to be forward variables, so this form ofBlock::Evalworks only with forward computation. -
Backward computation: In the C++ world,
Block::Evalcan accept gradient variables as its targets. We can create a Python API function, saybackward, which callsBlock::Evalwith gradient variables to do the backward computation.
-
-
The other form of
Block::Evalaccepts targets as operators:void Block::Eval(vector<Operator*> targets);
Somewhere in the C++ world, we can enumerate all optimization operators and use them as the target, so could we run the optimization step.
|
|
||
| For each parameter, like W and b created by `layer.fc`, marked as double circles in above graphs, `ConstructOptimizationGraph` creates an optimization operator to apply its gradient. Here results in the complete graph: | ||
|
|
||
|  |
There was a problem hiding this comment.
I think we should call A depends on B only if in every step running A requires running B. For example, we probably should not call "MSE" depends on "init" (however, according to the dependency chain, currently "MSE" depends on "init" in the graph). Otherwise we need to come up a way to let "init" only run once while doing training.
In my opinion we need two kinds of directed edges. One for dependency, one for data flow. And maybe for discussion we don't need to draw the intermediate variable. In the graph below the dotted line is data flow, the full line is dependency. In this representation, there is no cycle in the graph, and "MSE" no longer depends on "init".
User can call "init all" to do initialize, and call training later (which does not do init again, since there is no dependency).
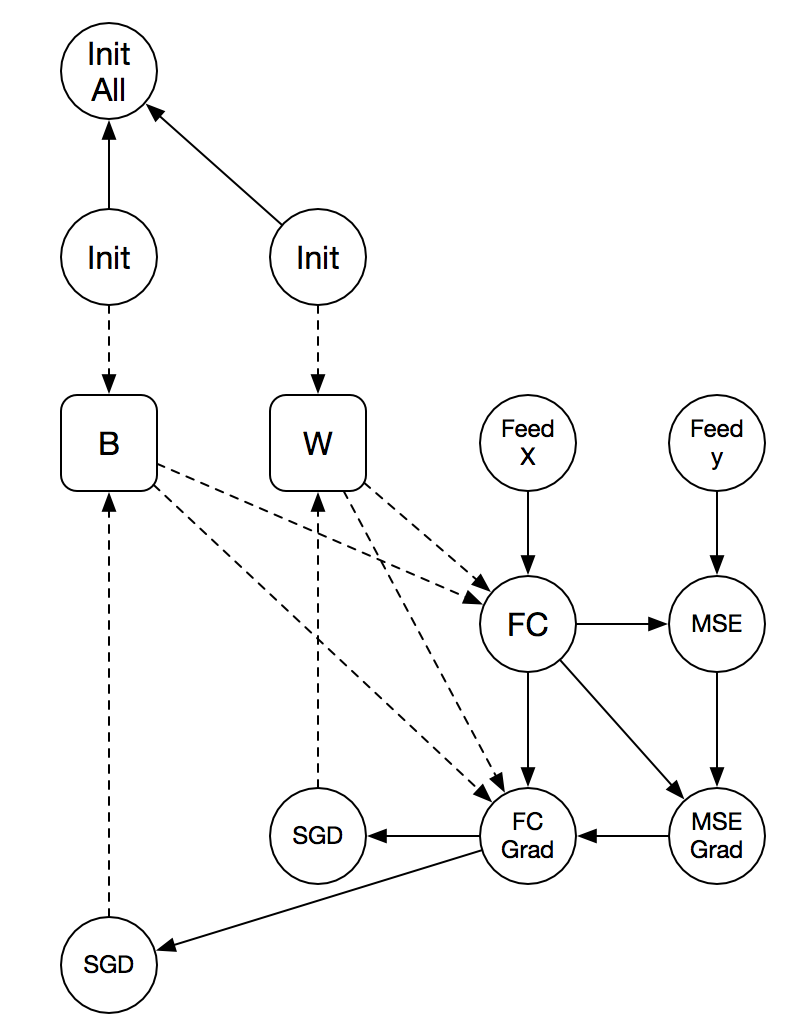
There was a problem hiding this comment.
Got it. I love this idea and the figure! I agree that there are two kinds of dependencies -- the data dependency and the execution dependency. Currently, we treat them as the same and represent them by the order of operators in array repeated OpDesc ops in protobuf message BlockDesc.
I am not sure if it is necessary to explicitly describe these two kinds of dependencies in our protobuf messages. A reason is that I am not sure what InitAll is -- is it a Var like those returned by operator binding functions, or is it an operator?
There was a problem hiding this comment.
Sorry, I should have make "init all" more clear. It's an OP that joins / merges all the dependency: it will run when all its dependencies are done, it's does nothing itself (only used to join the dependency). Maybe we can call it join or merge.
The reason behind why we need to explicitly describe these two kinds of dependencies is: the PaddlePaddle scheduler only need to schedule OP to run according to the dependency constraint (data flow is no longer a scheduling constraint). For example, in this case, even though "init" writes to var "B" (data flows from "init" to "B"), var "B" no longer depends on "init", so when doing optimization, "init" will not be scheduled.
There was a problem hiding this comment.
Another solution is TF's solution: there is no type var in the graph. A graph only has OP, and every directed edge is a tensor rather than var. A var is represented by a "var OP", which only have output (output the handle for read / write), but no input:
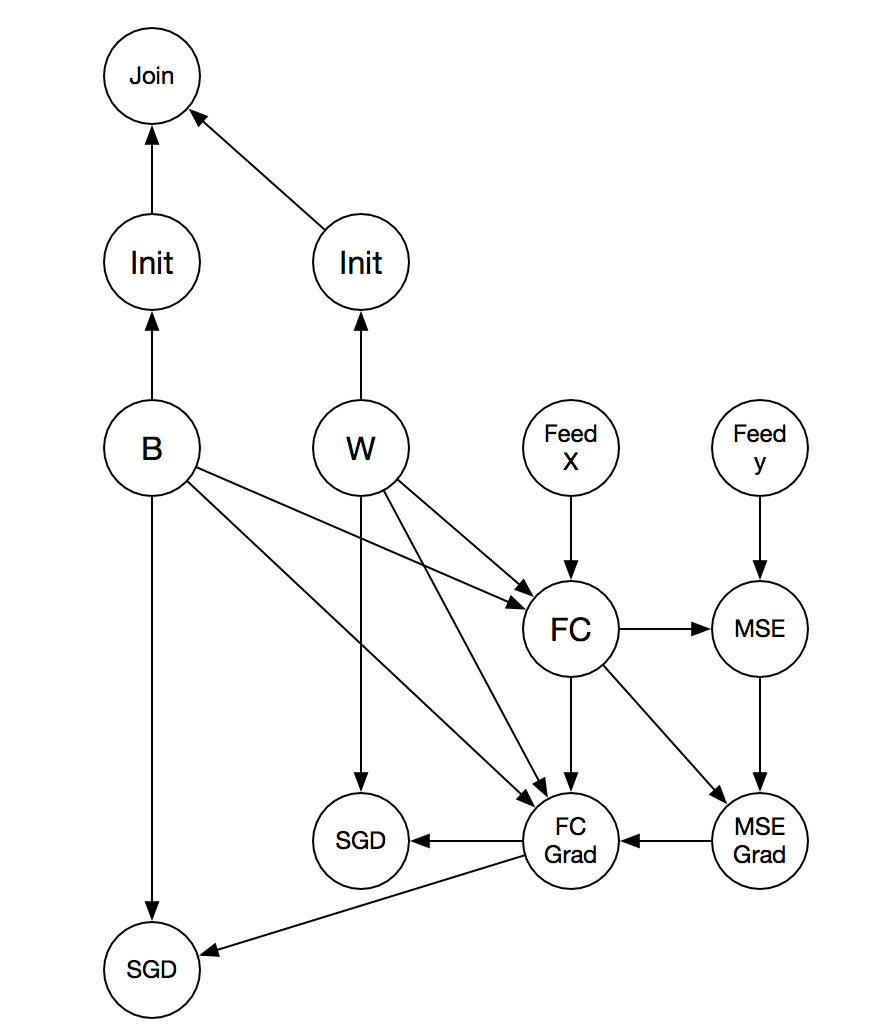
There was a problem hiding this comment.
Record the temporary conclusions from offline discussions:
- TensorFlow's graph representation embeds variables into operators, and
- requires users specify input, output, and dependent operators for each operator.
The specification of dependencies looks ugly. So let's follow our current design of using variables and operators.
 jacquesqiao
left a comment
jacquesqiao
left a comment
There was a problem hiding this comment.
LGTM! Run-once is a kind of solution of parameter initialization. Maybe there are some other ways. We can change this design doc when finding a better solution.
Fixes #3861