Update graph construction design doc #3862
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
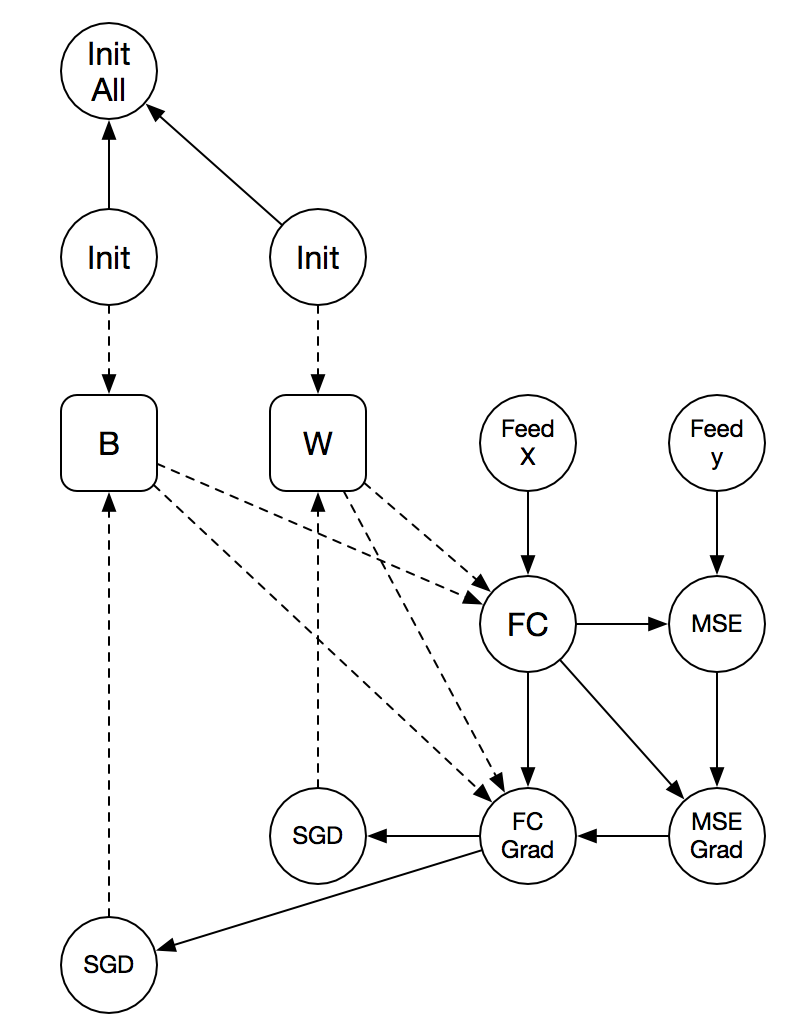
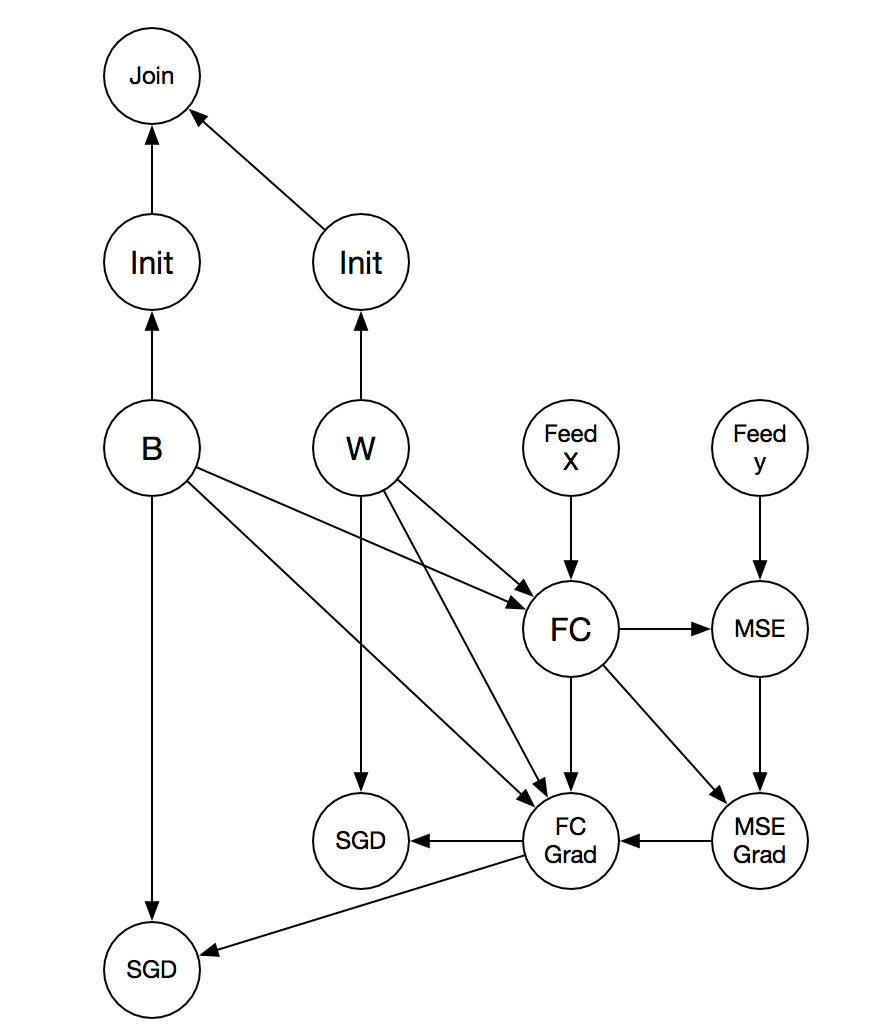
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Sorry, have some comment for the part that is not from this PR:
I think train should use the var returned by optimizer as argument, not cost. For example if two optimizer is connected with the cost, only specifying the cost the engine would have confusion of with optimizer to run.
Uh oh!
There was an error while loading. Please reload this page.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I think the training needs 1) the cost, and 2) the parameter to be optimized to minimize the cost.
The cost is specified in the invocation to
train.Parameters could be created by a layer function like
layer.fc, or the user viaW = paddle.Var(type=parameter, ...). Anyway, they are marked parameters and can be updated.So both cost and parameter are known prior to training. What do you think about this approach?
Uh oh!
There was an error while loading. Please reload this page.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I think it need the optimizer as well (Adam or Adagrad).
For example, it user do something like:
What optimizer will Paddle use for training? Maybe the code below is more concise:
However, I just realized the Python code you wrote is perhaps the V2 API, which maybe only allow one optimizer to be connected with the cost.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Yes. What I mean is that we can have two forms of
Block::Eval:One accepts targets of type
Variables:which is used to do forward computation. It traces only operators in
BlockDesc::opsbeforetargets.Forward computation: Because our Python API doesn't expose gradient variables to users,
targetshave to be forward variables, so this form ofBlock::Evalworks only with forward computation.Backward computation: In the C++ world,
Block::Evalcan accept gradient variables as its targets. We can create a Python API function, saybackward, which callsBlock::Evalwith gradient variables to do the backward computation.The other form of
Block::Evalaccepts targets as operators:Somewhere in the C++ world, we can enumerate all optimization operators and use them as the target, so could we run the optimization step.