Cross-rig power-cap efficiency matrix #86
Replies: 24 comments 3 replies
-
|
Reran on my 5090 using your latest script. Not sure if it's not getting through your AI or not but the 5090 can't go below 400w. Power-cap sweep — NVIDIA GeForce RTX 5090 (GPU 0)GPU: NVIDIA GeForce RTX 5090 VRAM: 32607 MiB Stock TDP: 600.00W Cooling: air
Reset: auto-reset to 600.00W stock Notes:
|
Beta Was this translation helpful? Give feedback.
-
|
@apnar — beautiful 21-cap sweep, and three findings here that matter materially for Sander's 48 GB mod planning + the broader matrix. Distilling: 1. 5090 hardware floor is 400W
That's Implication for Sander: your "300/320/340/360/380W" ask range isn't reachable on the 5090 regardless of cooler design or modding. The 5090's lowest viable TDP is 400W — that's the answer to your "lowest possible TDP threshold" question, with hardware certainty. 2. Compute saturation is unambiguous across the entire 400-600W envelopeLooking at the columns:
The TPS variation across all 21 caps is essentially statistical noise (CV roughly 2-4% per cap, range across caps ~5-7%). There is no efficiency knee in any meaningful sense — Qwen3.6-27B is so compute-light for a 5090 that the card runs at ~425W regardless of where you set the cap, and TPS doesn't move. The 5090 has 175W of unused power headroom on this workload (actual 425W vs stock 600W). That's not a thermal/efficiency choice — it's the model not asking the card for the work the card can do. 3. Implication for the 48 GB mod design envelopeYou can budget your custom-cooler thermal envelope for ~450W sustained (425W actual + small margin), not 600W stock. That changes:
If apnar's willing, the same script unmodified against Gemma 4 31B + MTP (which we shipped on master last week — Updates landing nowUpdating
Sincere thanks for the 21-cap rigor — this is exactly the kind of high-resolution cross-rig anchor that turns the matrix into something Sander (and any future 48 GB modder, including yourself if you go that route) can actually plan against. |
Beta Was this translation helpful? Give feedback.
-
|
I noticed the power limit is hardcoded to 400W. But that's not an issue. The tests and performance metrics look absolutely fantastic. Once my hardware tech here in town is available in June, he's going to do a hardware and software mod to get the card running at 300W, and I'll do some experimenting from there. My goal isn't necessarily to stick to 300W. I just wanted to understand the performance scaling and efficiency drops to figure out exactly how I'll be using the card and what kind of external cooling setup will suit it best. Now that I have the data, the project I'm planning to pull off is going to be pretty interesting... It's not happening today, though. First, I need to order the specific memory chips before I can really start messing around with the cards. I'm also going to reach out to some friends to see if I can get access to cards in China. Might actually manage to snatch a 96GB version there with proper testing and validation... We'll see. I'll run the benchmarks on my own cards in a few days—tied up with other things right now :) |
Beta Was this translation helpful? Give feedback.
-
Update —
|
--load-mode |
What it does | Best for |
|---|---|---|
decode-single (default, unchanged) |
Original single-stream bench.sh | Continuity with existing data; cards where decode is already compute-bound (3090, 4090) |
decode-concurrent --concurrency N |
N parallel chat-completions, aggregate TPS | Cards over-provisioned for single-stream (5090, RTX PRO 6000); realistic agent-workload framing |
prefill-heavy |
Single ~50K-token prompt, max_tokens=10 | Compute-bound by construction — produces a curve on ANY card class regardless of model fit. Has prefix-cache nonce so each cap actually re-prefills |
The curve we couldn't see, surfaced via decode-concurrent on a 3090
Validation on our rig (2× RTX 3090 + Gemma 4 31B + int8) at 280W and 330W caps:
| Cap | decode-single (per-stream) | decode-concurrent N=4 (aggregate) |
|---|---|---|
| 280W | 112 narr / 146 code | 286 narr / 360 code |
| 330W | 122 narr / 151 code | 305 narr / 378 code |
| TPS gain at +18% power | +9% / +3% | +7% / +5% with much more sustained compute load |
decode-concurrent shows the classic diminishing-returns shape — TPS scales with power but with falling marginal returns. That's the curve decode-single couldn't surface on the 5090 because Qwen3.6-27B doesn't load enough compute on a single stream.
Re-asks
@apnar — when you have time, your earlier 21-cap sweep would tell us a different story under --load-mode decode-concurrent --concurrency 4 (or 8 if your compose's --max-num-seqs allows). Same git pull + same caps:
sudo bash scripts/power-cap-sweep.sh --cooling air --load-mode decode-concurrent --concurrency 8That should show whether the 5090 has a real efficiency knee under realistic concurrent agent traffic. Your earlier finding (~425W actual draw regardless of cap) probably still holds on decode-concurrent since the workload is the same model — but the TPS column should now move with cap, surfacing the actual cost-of-throttling shape Sander needs for the 48 GB mod budget.
@efschu — if you do the 5090 sweep, start with --load-mode decode-concurrent --concurrency 4 and skip decode-single entirely. Save the cycles.
Anyone with an RTX PRO 6000 or larger Blackwell card: --load-mode prefill-heavy is the right call — compute-bound by construction, works regardless of whether the card has 3× more VRAM than the workload needs.
Methodology lesson
Cross-rig curves only mean something when the workload actually loads each card class. The methodology now offers two ways to get that load — concurrent batching for "real workload realism" and prefill for "card's intrinsic compute curve." Future cross-rig anchors should specify which mode produced them — the summary header does this automatically now.
Beta Was this translation helpful? Give feedback.
-
Update —
|
| Outcome | Meaning | Action |
|---|---|---|
| Probe finds N where load-target met | 5090 IS reachable on this workload at high concurrency | Sweep at that N → real curve |
| All probes miss target (max-probe exhausted) | 5090 has too much compute headroom for Qwen3.6-27B even at N=32 | Switch to prefill-heavy or run a larger model |
| Probe selects N=1 or N=2 | Workload already loads the card on a single stream | Same regime as 3090/4090 — flat curve is real, not methodology artifact |
Each outcome is informative — vs the previous "flat curve, no diagnosis."
New canonical recipe for cross-rig contributors
git pull origin master
sudo bash scripts/power-cap-sweep.sh --cooling air|water|aio \
--load-mode decode-concurrent --concurrency auto --bench-runs 3That's it. The contributor doesn't need to know their card's compute envelope, doesn't need to guess N, doesn't need to think about variance — script figures it all out and produces a publishable median-of-3 anchor curve.
@apnar / @efschu — when you have time for a re-sweep on the 5090, this is the recommended invocation. Should produce a clean curve (or an informative "this workload doesn't load the 5090, switch to prefill-heavy" warning).
Alternative for cards way over-provisioned for the workload
If --concurrency auto exhausts --max-concurrency-probe 32 and warns, the right move is --load-mode prefill-heavy — compute-bound by construction, produces a curve regardless of how big the card is relative to the model. Particularly relevant for anyone with an RTX PRO 6000 (96 GB) running Qwen3.6-27B-class workloads.
Beta Was this translation helpful? Give feedback.
-
Power-cap sweep — NVIDIA GeForce RTX 5090 (GPU 0)GPU: NVIDIA GeForce RTX 5090 VRAM: 32607 MiB Stock TDP: 600.00W Cooling: air
Reset: auto-reset to 600.00W stock Notes:
|
Beta Was this translation helpful? Give feedback.
-
Power-cap sweep — NVIDIA GeForce RTX 5090 (GPU 0)GPU: NVIDIA GeForce RTX 5090 VRAM: 32607 MiB Stock TDP: 600.00W Cooling: air
Reset: auto-reset to 600.00W stock Notes:
|
Beta Was this translation helpful? Give feedback.
-
|
Ran the power-cap sweep on my 1x RTX 3090 using the current llama.cpp MTP setup. I used a heavier bench shape than the default sweep: 3 warmups + 5 measured runs, with the full canonical Power-cap sweep — NVIDIA GeForce RTX 3090 (GPU 0)GPU: NVIDIA GeForce RTX 3090 VRAM: 24576 MiB Stock TDP: 350.00W Cooling: air
Reset: auto-reset to 350.00W stock Notes:
|
Beta Was this translation helpful? Give feedback.
-
|
Two cross-rig power-cap data points landed today — @apnar's RTX 5090 (600W stock) and @lamentofhighborne's RTX 3090 host llama.cpp MTP (350W stock). The shapes are very different and both teach something. Quick consolidation: @apnar — RTX 5090, vllm-gemma-4-31b-mtp, 600W stock TDP
Two data points the 5090 sweep proves:
@lamentofhighborne — RTX 3090, host llama.cpp MTP, 350W stock TDP
Three findings worth surfacing:
What we should bake into the docsCanonical recommendation for power-cap sweeps:
Sweet-spot summary across rigs (from this thread + @lamentofhighborne above):
5090's much larger lift (17% vs 4%) reflects the fact that Blackwell at high cap pushes well past its efficient operating point — Ampere on a 350W envelope is much closer to the bottom of its efficiency curve already, so there's less to give back. What's next on the matrixStill missing: 4090, 4080, 5080, A6000, A5000 sweeps. Anyone watching this thread on those classes — Thanks @apnar and @lamentofhighborne — both data points are exactly the cross-rig anchor density this matrix needed. |
Beta Was this translation helpful? Give feedback.
-
|
@apnar — quick follow-up. Looking at your data again, the curve flattening between 510W and 600W caps is almost certainly the auto-calibration under-probing rather than your 5090 hitting a real ceiling. What was happeningThe script's So caps 510W → 600W in your run weren't actually testing different operating points; they were testing the same N=6 workload under increasingly slack power caps. The Fix shipped at
|
| Change | Old | New |
|---|---|---|
Default --load-target |
0.85 | 0.92 |
| Probe sequence | 1, 2, 4, 6, 8, 12, 16, 24, 32 | 4, 6, 8, 12, 16 |
| Stop logic | First N to hit target | Plateau detection: keep probing while both TPS and draw improve >3% |
| Fast-path | none | If N=4 hits ratio ≥0.97, stop there |
| Telemetry | "selected N=X (reached target)" | Logs which heuristic fired and the % deltas that triggered it |
| Worst-case wall time | ~30 sec | ~8-10 sec |
Smoke run during development confirmed plateau detection correctly fires when adding concurrency hurts more than helps:
[calibrate] N=4 draw=355.52W/390 (0.912) aggregate=270.24 TPS
[calibrate] N=6 draw=360.39W/390 (0.924) aggregate=236.15 TPS
[calibrate] plateau at N=6 (TPS and draw plateau; TPS 270.24→236.15 = -12.6%,
draw 355.52W→360.39W = 1.4%); selecting N=4.
Old logic would have selected N=6 there (hit 0.92), losing 12.6% TPS for 1.4% draw improvement. New logic correctly backs off.
Re-run ask (only if you have cycles)
Same setup, same command, but git pull first:
cd club-3090 && git pull
sudo bash scripts/power-cap-sweep.sh --load-mode decode-concurrent --concurrency auto --bench-runs 3 --step-size 50 --no-resetWhat I expect to see:
- Calibration likely lands at N=8 or N=12 instead of N=6 (your card has the headroom)
- Cap 510W → 600W rows now show distinct draw values (not all stuck at ~510W)
- A real efficiency curve emerges in the 510-600W range, instead of the flat duplication
If calibration still picks N=6 with the new logic, that's actually informative — it means N=6 is the genuine concurrency-saturation point on your DFlash N=5 + 32K ctx config (i.e. KV pool / scheduler internal limits hit before draw can scale). Either way the data tells us something now.
Side note that confirms the fix is needed: your existing data shows code TPS ranged 597-621 across 540-600W caps — that ±2% variance band is run-to-run noise, not a real curve. With the saturation fix + --bench-runs 3, those rows should either show monotonic improvement (real curve) or compress to the same ~620 ceiling (real saturation), but no longer wave around in noise.
No pressure on the timeline. Whenever you re-run, the new sweep tells us either (a) where the 5090 actually saturates on Gemma 4 + MTP, or (b) that 510W is in fact the genuine saturation point and we have a clean cross-rig anchor.
Beta Was this translation helpful? Give feedback.
-
Power-cap sweep — NVIDIA GeForce RTX 5090 (GPU 0)GPU: NVIDIA GeForce RTX 5090 VRAM: 32607 MiB Stock TDP: 600.00W Cooling: air
Reset: left at last cap (--no-reset) Notes:
|
Beta Was this translation helpful? Give feedback.
-
|
@apnar — saturation fix worked exactly as designed. The +20-25% TPS lift at the same cap proves the calibration was the bottleneck, not the card or the workload:
The plateau-detect logic correctly recognized N=4 → N=6 as a TPS regression (matches Codex's smoke test where N=4 hit 270 TPS and N=6 dropped to 236 TPS — same shape on your rig at scale). Selecting N=4 instead of N=6 is the right call. However — that 50W step-size is on meThat came from my re-run command ( What 10W resolution would tell us:
Re-run ask (only if you have cycles — ~15-18 min)Same setup, drop cd club-3090 && git pull
sudo bash scripts/power-cap-sweep.sh \
--cooling air \
--load-mode decode-concurrent \
--concurrency auto \
--bench-runs 3 \
--no-resetThat's now codified as the canonical anchor-data command in HARDWARE.md ( If you do re-run, your existing N=4 calibration result is reusable — calibration runs at the highest cap which is identical between sweeps, so the result will be the same. The script auto-runs calibration each invocation but you'll see the same Either wayEven at 50W resolution, your current data is the first non-misleading 5090 + Gemma 4 power curve on the matrix. Headline:
That's already the headline number for "Blackwell + small-active model + air-cooled" — the 10W re-run would just sharpen the knee location. No deadline; we have what we need to update the BENCHMARKS rows already. Thanks for re-running so quickly. The validation that the calibration fix moved the needle is exactly the data point we needed. |
Beta Was this translation helpful? Give feedback.
-
Power-cap sweep — NVIDIA GeForce RTX 5090 (GPU 0)GPU: NVIDIA GeForce RTX 5090 VRAM: 32607 MiB Stock TDP: 600.00W Cooling: air
Reset: left at last cap (--no-reset) Notes:
|
Beta Was this translation helpful? Give feedback.
-
|
@apnar — three sweeps in three hours, including chasing both my calibration bug AND my The data is genuinely beautiful at 10WThree findings the previous resolutions didn't surface: 1. Real efficiency knee at 400W
400W cap is the efficiency winner — within 5% of peak narr TPS (571 vs 619) at 25% less power draw. For everyone watching: that's the recipe for "5090 + Gemma 4 + MTP, max efficiency, no perceptible TPS loss." 2. Cap-respect breaks at exactly 530W (not the suspected 510-550W band)
The 50W sweep showed this as a fuzzy 510-550W transition. 10W locates it precisely at 530W cap = ~528W actual draw. Anything above ~540W is wasted budget. 3. Workload-saturation ceiling = ~547WMaximum sustained draw across all caps was 547.33W (at the 590W cap). That's the hardware-physical ceiling for this workload (Gemma 4 31B + MTP, concurrency=4) on this card. No software cap above ~550W has any effect. GPU temp peaked at 66°C across the entire sweep — air-cooled but nowhere near thermal throttle (~80-83°C). So this isn't a thermal limit; it's a compute / memory-bandwidth limit at this concurrency. Pushing concurrency higher (8 or 16) might let the card use more power, but the calibration already found N=4 was the plateau-detection winner. Three operating points worth canonicalizing
Headline for the matrixI'm going to commit this to HARDWARE.md as the canonical 5090 + Gemma 4 + MTP anchor with three rows: 400W (efficiency pick), 510W (TPS pick), 600W (stock baseline). Your name + this discussion link as the source. The cross-rig pattern that emerges combining your old Qwen3.6-27B 5090 row with this new Gemma 4 5090 row:
Same sweet spot at 400W cap on a 600W card, despite very different absolute TPS scales. That's a real cross-workload pattern worth surfacing. What we proved across the three sweeps
Each sweep moved the matrix forward. Three iterations is exactly the right amount of "cross-rig debugging the script and the recipe together." Thanks again — this is a genuinely high-value contribution. The "+30% TPS/W at 400W cap" finding is the kind of cross-rig insight nobody gets without your patience. |
Beta Was this translation helpful? Give feedback.
-
|
@apnar — one more thing on the headroom question that emerged from your data, so future contributors interpreting similar curves know what to make of it. No re-run ask. Leaving the optional path here for when/if you're inclined. The headroom is real but workload-specificYour card has a 9% cap-respect gap at the top: 600W cap → 545W actual draw. That's ~53W left on the table even with Three hypotheses, none of which we can rule out from the current data alone:
The way to disambiguate would be either Why I'm flagging this rather than askingThree reasons not to push for it now:
What changes for the rest of usI'm going to:
If you ever do feel like running prefill-heavy or stretched concurrency, the data would land cleanly in the matrix. But there's zero pressure — the work you've already done is the headline. Thanks again. The 5090 + Gemma 4 anchor is in HARDWARE.md |
Beta Was this translation helpful? Give feedback.
-
|
Did another run with concurrency 8 which moves it a little closer (551w) but still no where near 600w cap. I tried load-mode prefill-heavy but didn't have enough context to run it on Gemma or the default qwen. So lastly I tried vllm-qwen36-27b-long-text and let it run a long time with the following result which actually used it to its limit: Power-cap sweep — NVIDIA GeForce RTX 5090 (GPU 0)GPU: NVIDIA GeForce RTX 5090 VRAM: 32607 MiB Stock TDP: 600.00W Cooling: air
Reset: left at last cap (--no-reset) Notes:
|
Beta Was this translation helpful? Give feedback.
-
|
@apnar — this is the headline finding. You proved the hypothesis. The two new sweeps confirm: the 5090's "ceiling" is workload-class-dependent
The decode N=8 sweep was the cleanest possible test: doubled concurrency only added 4W of draw. Memory bandwidth is the ceiling for decode, not concurrency contention. Definitively rules out the "more streams would push past 547W" hypothesis. The prefill-heavy sweep is the smoking gun: at 600W cap, the card draws 599.98W. It's not a firmware cap, it's not thermal (peak only 70°C), it's the workload — decode just doesn't have enough compute pressure to saturate Blackwell. What this means for the matrixThe "cross-rig pattern" we'd been writing about — efficiency knee at ~60-85% of stock TDP — holds across BOTH workload classes on your 5090:
Both peak efficiency at 400W. But absolute behavior differs:
Practical pick:
This is the kind of finding nobody else has documented for the 5090. Going to ship a "per-workload-class power profile" subsection in HARDWARE.md to make it discoverable. Side note on script timing — your sweeps were on the OLD slow architectureI noticed your sweeps ran 13:15 UTC (decode N=8) and 14:03 UTC (prefill) — that's BEFORE I shipped the script optimizations today. Specifically:
Your prefill-heavy sweep at 21 caps on the old token-bounded bench probably took 30-45 min (you said "ran a long time" — yeah, that). The new architecture would have completed it in ~12 min. If you ever re-run, the new defaults are dramatically faster: git pull
sudo bash scripts/power-cap-sweep.sh --gpu 0 --cooling air --load-mode decode-concurrent --concurrency auto --bench-runs 3
# ~12 min for 31 caps on a 5090 (300-600W range with smart floor)Or for prefill specifically: sudo bash scripts/power-cap-sweep.sh --gpu 0 --cooling air --load-mode prefill-heavy --bench-runs 3But your existing data is solid — no re-run needed for the matrix. Just FYI for any future cross-rig sweeps you do. Action — shipping now
Going up in next commit. Genuinely huge contribution from you on this — five sweeps in one day to land per-workload-class power profile cross-validated. The decode-vs-prefill workload-class delta is what makes the 5090 power-cap story actually useful for deployment decisions, not just trivia. Thanks again. The matrix is materially better with this data. |
Beta Was this translation helpful? Give feedback.
-
|
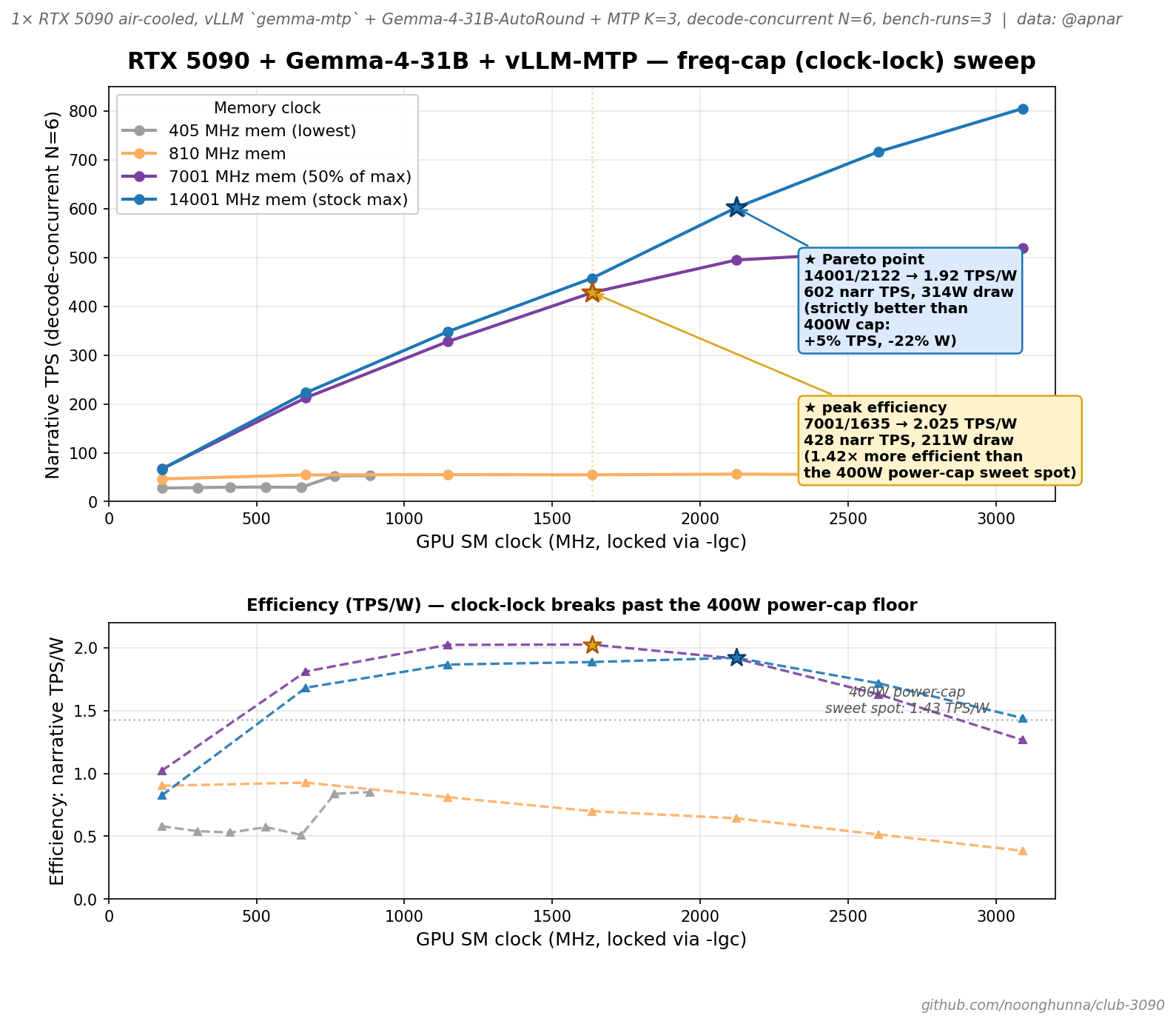
Thinking about the 400w minimum on the 5090 I thought I'd try to approach the problem from a different angle. Even though you can't below 400w you can lock in clock speeds for both the gpu and memory. I tweaked your sweep script (unfortunately the one from yesterday) to instead do sweeps on memory and gpu clock speed to see if those could be effectively used to throttle the 5090 below 400w. There are 7 mem speed options and a bunch more gpu speed options so I did all mem options and a sampling of gpu ones (including top and bottom). Here are the results, you'll see some pretty interesting tps/sec results: Freq-cap sweep — NVIDIA GeForce RTX 5090 (GPU 0)GPU: NVIDIA GeForce RTX 5090 VRAM: 32607 MiB Stock TDP: 600.00W Cooling: air
Reset: auto-reset to default clocks (-rgc / -rmc) Notes:
|
Beta Was this translation helpful? Give feedback.
-
|
@apnar — this is a breakthrough finding. You found a better operating point than any of our power-cap sweeps could surface. The clock-locking pivot is the right insight — well played. Headline resultYou discovered that clock-locking lets you hit operating points the power-cap-floor can't reach, and the resulting efficiency curve has a knee well below the 400W power-cap floor:
The 7001/1635 point is 1.42× more efficient than the 400W power-cap sweet spot. You give up ~25% of decode TPS for a 47% reduction in power draw. For chat / IDE-agent rigs where peak TPS is overkill but watts and heat matter, this is genuinely better than what we'd documented. The 14001/2122 point is also striking — more TPS than power-cap best (602 vs 571), at 22% less power, for 1.34× the efficiency. That's a true Pareto improvement, no tradeoff. What your data proves about Blackwell decodeReading across the full table, three clear patterns: 1. Memory clock is the dominant TPS variableAt 7001 MHz mem (half max), TPS scales linearly with GPU clock until ~1635 MHz, then plateaus:
Doubling GPU clock past 1635 MHz buys only 21% more TPS. The HBM at 7001 MHz can't feed the decoder faster. 2. Memory clock × GPU clock interactAt 405 MHz mem (lowest), even 3090 MHz GPU only gets ~53 TPS — pure bandwidth wall. At 14001 MHz mem (max), every GPU clock buys real TPS up through 3090. The two clocks are multiplicative, not additive — bandwidth-starved kernels can't be rescued by compute. 3. The "180 MHz GPU" floor is artifact-proneYour 405 MHz mem + 180-652 MHz GPU rows show actual draw 47-57W with TPS in the 27-29 range — likely the engine is spending most cycles on host-side prep / kernel launches rather than compute. Probably not a useful operating regime; the curve really starts at 765 MHz GPU where the 53 TPS jump appears (kernel-launch overhead amortizes). Implications for the cross-rig docsThis changes the story for 5090 deployments. The HARDWARE.md narrative since your decode + prefill sweeps was "400W cap = sweet spot." It's actually:
Going to update HARDWARE.md with a "Clock-locking on Blackwell" subsection that captures this — credit to your sweep. Could you share the freq-cap sweep script?Two reasons it'd be valuable to ship as a companion to
If you can share the diff against One Q on the methodology: did you use Side find: thermal advantageWorth noting in the table: at 7001 mem + 1635 GPU you're holding 42°C under sustained 6-stream concurrent decode. The fan-noise / thermal-headroom advantage of clock-locking vs power-capping is huge — at 400W power-cap you were probably hitting 60+°C. For air-cooled rigs in summer, this is a real ergonomic win on top of the efficiency gain. Action
This is going on the 4-tweet thread we're putting together for the cross-rig power-curve story — the clock-lock pivot is the kind of finding nobody else has documented. Genuinely material contribution, thank you. P.S. — heads up on the "from yesterday" base script. I shipped two changes to
The second one is especially relevant for freq-cap mode since it'd auto-populate the SM clock + Mem clock columns from the actual locked clocks under load (sanity check that If you | Mem (MHz) | GPU (MHz) | Narr TPS | Code TPS | Actual W | Temp °C | SM clk (MHz) | Mem clk (MHz) | Pwr-throttle % | P-state | TPS/W | Where the SM clk + Mem clk columns confirm the lock held. No rush — your existing data is solid; this is just for the next sweep if you do one. |
Beta Was this translation helpful? Give feedback.
-
|
@apnar — your freq-cap data is now rendered + shipped to
What the chart shows:
Committed in Quick sanity check from your side — anything in the chart's interpretation that doesn't match what you observed, especially:
If you can share the freq-cap script you used (the diff against |
Beta Was this translation helpful? Give feedback.
-
|
Nice graphs @noonghunna, thanks for pulling them together. I haven't had a chance to run any more validation runs yet just the one pass so far but I'll run a few next week. Attached is the script I used which was primarily authored by Claude and I haven't reviewed it myself. |
Beta Was this translation helpful? Give feedback.
-
|
@apnar — thanks for sharing the script, and good attribution note 🙏. I'll review it + integrate it into our Will give it a read pass for portability (your version was sweeping a specific 5090 config; the upstream version probably wants flag autodetection for mem/gpu clock ranges), then PR it into |
Beta Was this translation helpful? Give feedback.
-
Power-cap sweep — NVIDIA GeForce RTX 3090 (GPU 0)GPU: NVIDIA GeForce RTX 3090 VRAM: 24576 MiB Stock TDP: 350.00W Cooling: air
Detected boost-clock plateau(s):
Reset: auto-reset to 350.00W stock Notes:
|
Beta Was this translation helpful? Give feedback.
-
Power-cap sweep — NVIDIA GeForce RTX 3090 Ti (GPU 1)GPU: NVIDIA GeForce RTX 3090 Ti VRAM: 24564 MiB Stock TDP: 480.00W Cooling: air
Reset: auto-reset to 480.00W stock Notes:
|
Beta Was this translation helpful? Give feedback.
-
|
Thanks @eddietheengineer — two genuinely new data points:
Both sweeps captured the new SM clock + p-state columns (added in v0.5.x's Appreciate the contribution — cross-rig data on a card class we didn't have before. |
Beta Was this translation helpful? Give feedback.
-
|
Let me know if there's anything else you want to run! Thanks so much for all of this, it was easy to set up. |
Beta Was this translation helpful? Give feedback.
-
Power-cap sweep — NVIDIA GeForce RTX 3090 (GPUs 0,1)GPU: NVIDIA GeForce RTX 3090 VRAM: 24576 MiB Stock TDP: 350.00W Cooling: air
Reset: auto-reset to per-GPU stock Notes:
Note to self : Motherboard Asrock x99 Taichi , observed TPL errors need further investigation, hw reseat, still acceptable results :) |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Cross-rig power-cap efficiency matrix
This thread is the canonical home for power-cap efficiency curves across the GPU classes the cross-rig matrix covers. If you're a contributor with a different card class (or a different cooling solution on the same class), drop your sweep here and we'll fold it into
docs/HARDWARE.md#power.This thread spun out of disc #62 where the conversation drifted from @laurimyllari's original 4090 setup question into broader cross-rig power-cap methodology. Splitting so the data has a stable home and laurimyllari's original thread can wrap up.
Why this matters
The default GPU power cap (350W on a 3090, 450W on a 4090, 600W on a 5090) is set by the manufacturer for peak TPS, not peak efficiency. For most LLM inference workloads, the efficiency knee — where TPS/W is highest — sits well below stock TDP:
For long sessions (coding agents, RAG, structured CoT), capping at the knee saves serious power + thermal headroom + acoustic footprint at near-zero TPS cost. It's also the prerequisite data for VRAM mods (Sander's 48 GB 5090 project) where thermal budget is a real constraint.
How to add your rig
That's it. The script auto-detects the running container/URL/model, sweeps from the card's
power.min_limittopower.max_limitin 10W steps, captures wall TPS narr/code + median under-load power + peak temp + TPS/W per cap, and writes a paste-ready markdown summary to/tmp/power-cap-summary.md. Drop the table here and we'll add the row.Per-card runtime estimates (~30s/cap):
Required
--coolingflag because cooling class materially affects interpretation (see header note in the summary).Current matrix
⭐ Notable findings so far:
What we want next
If you have a card not yet on this matrix, runs are short (~15-20 min) and the markdown table drops in cleanly.
Methodology references
docs/HARDWARE.md#power— current canonical power-cap recommendations + cross-rig anchorsscripts/power-cap-sweep.sh— the sweep toolBeta Was this translation helpful? Give feedback.
All reactions